You are the mean of all your peers
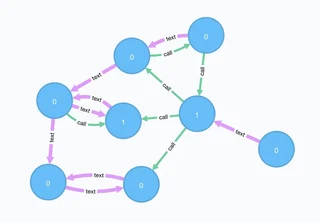 Network of dummy personas and their interactions
Network of dummy personas and their interactionsLet’s look at A graph containing vertices (persons) and edges (interactions, i.e. call or text) which might look like this graph of social interactions, 1 denotes the bad people we know of. Having loaded the graph into a graph database like neo4j allows for easy queries of the social network of a :Person. To check the network for hidden terrorists, I select other nodes which are up to 3 edges away from the original node and calculate the fraudulence as the average of all its neighbours, i.e. their interactions
MATCH (source:Person)-[:call|text*1..3]-(destination:Person)
RETURN source.name, source.known_terrorist, avg(destination.known_terrorist)
which will give the following result:
╒═════════════╤════════════════════════╤══════════════════════════════════╕
│"source.name"│"source.known_terrorist"│"avg(destination.known_terrorist)"│
╞═════════════╪════════════════════════╪══════════════════════════════════╡
│"Gabby" │0 │0.13333333333333336 │
├─────────────┼────────────────────────┼──────────────────────────────────┤
│"Esther" │0 │0.30434782608695654 │
├─────────────┼────────────────────────┼──────────────────────────────────┤
│"Charlie" │0 │0.3333333333333333 │
├─────────────┼────────────────────────┼──────────────────────────────────┤
│"David" │0 │0.3589743589743589 │
├─────────────┼────────────────────────┼──────────────────────────────────┤
│"Terrorist" │1 │0.29629629629629634 │
├─────────────┼────────────────────────┼──────────────────────────────────┤
│"Bob" │0 │0.3448275862068965 │
├─────────────┼────────────────────────┼──────────────────────────────────┤
│"Fanny" │0 │0.2950819672131147 │
├─────────────┼────────────────────────┼──────────────────────────────────┤
│"Alice" │1 │0.31111111111111117 │
└─────────────┴────────────────────────┴──────────────────────────────────┘
Interestingly, David seems to be the one best connected to the terrorists/fraudsters.
When breaking down the fraudulence by type of relationship call|text as separate features this can easily be achieved by the following code snippet. It might look a bit intimidating, but is used to get a more efficient query plan. Instead of reading the graph twice, a single pass over the data is enough which
MATCH p = (source:Person)-[:call|text]-(destination:Person)
RETURN
source.name as Vertex,
source.known_terrorist as known_terrorist,
apoc.coll.avg(COLLECT(
CASE WHEN ALL(r in relationships(p) where type(r)='call') THEN destination.known_terrorist ELSE NULL END
)) as type_undir_1_call,
apoc.coll.avg(COLLECT(
CASE WHEN ALL(r in relationships(p) where type(r)='text') THEN destination.known_terrorist ELSE NULL END
)) as type_undir_1_text,
apoc.coll.avg(COLLECT(
destination.known_terrorist
)) as type_undir_1_any
resulting in:

Fraud by type of relationship
The following jupyter notebook outlines how to use python to get a couple more alternate variants of this query and finally reshape the results.
now in spark
For a small graph neo4j is a great tool — but assuming the data is larger a different tool is requried. There, hadoop comes into play. Spark offers some graph computation capabilities on Hadoop. The graphFrames package contains a subset of cypher patterns which ease the adoption of graph tasks in the distributed context of Hadoop.
The CSV files are read directly into spark. Then, the graphFrames library is used to resolve the cypher pattern.
NOTE: currently the cypher patterns supported are rather minimal! Also scalability is questionable as the patterns are resolved using JOINS and not using an BSP iterative operator. https://stackoverflow.com/questions/41351802/partitioning-with-spark-graphframes
For this minimal dataset at least broadcast hash joins can be used (i.e. map side join)

Map side JOIN execution plan of spark
Execution plan for resolution of cypher patterns — outlining that plain joins are used.
Also, aggregations need to be performed outside of the graph processing library, i.e. in this case in plain spark:
val friends: DataFrame = g.find("(a)-[e]->(b)")
friends.show
friends.groupBy('a).agg(mean($"b.fraud").as("fraud"))
.withColumn("id", $"a.id")
.withColumn("name", $"a.name")
.withColumn("fraud_src", $"a.fraud")
.drop("a")
.show
Computing any of the combined queris as before gets a bit laborious as only few cypher patterns are supported out of the box. Here I build the \[*1..3] by hand:
val f1: DataFrame = g.find("(a)-[e1]->(b)")
.withColumn("level", lit("f1"))
.withColumnRenamed("a", "src")
.withColumnRenamed("b", "dst")
.select("src", "dst", "level")
val f2: DataFrame = g.find("(a)-[e1]->(b);(b)-[e2]->(c)").withColumn("level", lit("f2"))
.withColumnRenamed("a", "src")
.withColumnRenamed("c", "dst")
.drop("b")
.select(f1.columns.map(col _): _*)
val f3: DataFrame = g.find("(a)-[e1]->(b);(b)-[e2]->(c);(c)-[e3]->(d)").withColumn("level", lit("f3"))
.withColumnRenamed("a", "src")
.withColumnRenamed("d", "dst")
.drop("b", "c")
.select(f1.columns.map(col _): _*)
val friendsMultipleLevels = f1
.union(f2)
.union(f3)
val fFraud = friendsMultipleLevels.groupBy('src, 'level).agg(avg($"dst.fraud") as "fraudulence")
fFraud
.groupBy("src")
.pivot("level")
.agg(max('fraudulence)) // type of aggregation not really relevant here ... as only a single value can show up
.withColumn("id", $"src.id")
.withColumn("name", $"src.name")
.withColumn("fraud_src", $"src.fraud")
summary
A lot is happening in the space of distributed graph analytics. Neo4j is pushing spark support within the opencypher project. Recently, https://github.com/opencypher/cypher-for-apache-spark was released — still in the alpha stage it CAPS will bring more comprehensive support for cypher queries on spark.
All the code can be found on github: https://github.com/geoHeil/graph-playground
edit
How to Perform Fraud Detection with Personalized Page Rank outlines similar use cases using a personalized weighted page rank.
