Learnings from my master thesis with an industrial partner
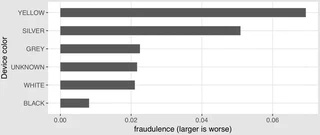 Fraud potential per device colour 😄
Fraud potential per device colour 😄I started working on my Master’s thesis in the Summer of 2016 at T-Mobile in Austria. Now, having successfully completed the project and graduated I want to summarise my learnings.
data
My thesis basically resembled a data science project. When starting out, I began to identify possible data sources. Initially, the data which was easily accessible was explored.
legacy IT jungle
The overall process to identify usable data was rather lengthy, as well as data cleaning.
metric
As my project dealt with fraud prediction you can already imagine that the data was heavily imbalanced, which means that some commonly used metrics to evaluate machine learning no longer make sense. For example, accuracy can easily be near 100% when only a single majority class is predicted. Some more complex metrics exist but it turned out that these were not easily understood by business users.
In my thesis, I propose an alternative. Based on Bahnsen’s cost-sensitive classification python package I develop a cost matrix unique for the telecommunication industry. This new metric which reflects actual business interest is not only
- not affected by the class imbalance but also
- easier to communicate
as risk and potential cost can be translated into savings, i.e. money which is well understood by the business.
cross validation
All too often, regular k-fold cross-validation procedures are used as these are readily available. However, most datasets have an intrinsic reference to time. Not considering it may lead to results which are worse (when used for real) compared to what was reported by experiments in the lab.
Sometimes randomization and stratification are used to smooth things out - but they are not helpful in this context.
For my dataset new devices occur over time. Additionally certain contracts are also only introduced at some point in time and available thereafter.
A regular time series cross-validation like scikit-learn TimeSeriesSplit can go a long way.
I decided to roll something custom which even better reflects the actual business process as in my case feedback for the model is not available instantly, but only after a couple of months have passed by:
Custom cross-validation reflecting actual business processes
time management
Working with an industrial partner always means that also other projects are important and it will not be possible to focus 100% on the own project - in my case my Master’s thesis. In my case, this meant building out their hadoop based data lake. This consumed a lot more time than initially expected. However, this also gave me access to real interesting data and allowed me to better understand the quirks of distributed systems in production. Still, from times it was a bit hard to focus on my own project. But it worked out well and I learned a lot.
summary
I had a great time at T-Mobile Austria during my Master’s thesis, learned a lot and took over quite some responsibilities. Thank you all who helped me when I had qustions or was stuck in dead ends.
Completing the Master’s immediately raises the question of what comes next. For me, this means that I will work on a Ph.D. If everything works fine I will hopefully be able to keep my industry partner.
