From hello-world to simple pipelines

Welcome 😄 to this blog series about the modern data stack ecosystem.
post series overview
This is part 1, giving a basic introduction – from the first steps of the hello-world to an initial fully-fledged data pipeline.
The other posts in this series:
- overview about this whole series including code and dependency setup
- basic introduction (from hello-world to simple pipelines)
- assets: turning the data pipeline inside out using software-defined-assets to focus on the things we care about: the curated assets of data and not intermediate transformations
- a more fully-fledged example integrating multiple components including resources, an API as well as DBT
- integrating jupyter notebooks into the data pipeline using dagstermill
- working on scalable data pipelines with pyspark
- ingesting data from foreign sources using Airbyte connectors
- SFTP sensor reacting to new files
hello-world
Here, you will write the first job and are introduced to the UI components of dagster.
The official tutorial also gives a good introduction: https://docs.dagster.io/tutorial/intro-tutorial/single-op-job
Firstly take a look of the user interface of dagster and take a read: https://docs.dagster.io/concepts/dagit/dagit to better understand the various components. In short:
- the factory room shows statistics about recent jobs
- the job shows the graph of the operations (DAG) which are performed in order
- on the launchpad a new job can be triggered with a specific configuration
- logs of a job are available in the runs tab
A simple say_hello_job graph with a hello function outlines the most basic functionalities.
@op
def hello():
"""
An op definition. This example op outputs a single string.
For more hints about writing Dagster ops, see our documentation overview on Ops:
https://docs.dagster.io/concepts/ops-jobs-graphs/ops
"""
return "Hello, Dagster!"
Simply by adding the @op annotation, dagster understands that this particular function should show up as a step (in case we create a graph of the various operations) in the user interface.
Any additional documentation (such as the docstring) is understood by dagster and made available in the UI.
With the: @job annotation, a new job is created.
@job
def say_hello_job():
"""
A job definition. This example job has a single op.
For more hints on writing Dagster jobs, see our documentation overview on Jobs:
https://docs.dagster.io/concepts/ops-jobs-graphs/jobs-graphs
"""
hello()
This example job (say_hello_job) only contains the hello operation (a single step graph).
Go to the launchpad and run the say_hello_job.
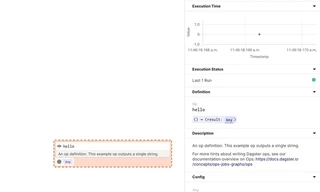
Furthermore, take note of the:
- statistics like runtime stats which are tracked automatically
- as well as the documentation created by the docstring are available.
Regular Python type hints could be used to also in the user interface to show the specific input or output type of the operation.
Commonly, dataframe-like functionalities are used in data pipelines where each column has a specific type and perhaps comment. For more details, see:
- https://docs.dagster.io/integrations/pandas#validating-pandas-dataframes-with-dagster-types
- https://docs.dagster.io/tutorial/advanced-tutorial/types
- https://docs.dagster.io/concepts/types
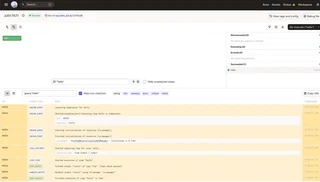
Take a look at the logs. In particular, the excellent visualization and structured logging capabilities.
You will observe how the text: Hello, Dagster! is returned as a result (but nothing is printed just yet).
adding logging
The first job did not log the outputs of Hello, Dagster!.
Let us add a second one:
@op
def log_hello(hello_input:str):
"""
An op definition. This example op is idempotent and outputs the input but logs the input to the console.
"""
get_dagster_logger().info(f"Found something to log: {hello_input}")
return hello_input
and chain it together in a new graph:
@job
def say_hello_job_logging():
"""
A job definition. This example job has two serially dependent operations.
For more hints on writing Dagster jobs, see our documentation overview on Jobs:
https://docs.dagster.io/concepts/ops-jobs-graphs/jobs-graphs
"""
log_hello(hello())
The Operations can be nested like regular python functions.
Take a look at the say_hello_job_logging graph in dagit:
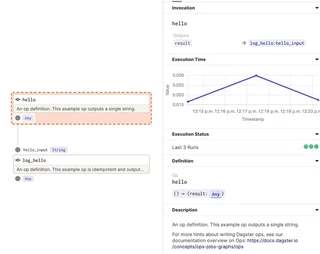
Now two nodes show up in the graph. The results of the first step can be passed over into the next step (operation).
Furthermore, the structured log message for the greeting can be identified when executing this job.
adding configuration
Usually, a job needs to be configurable as perhaps different resources need to be used in different environments. Perhaps secretes or paths/prefixes might be unique for development and production.
say_hello_job_configuration showcases this by making the greeting configurable.
A name can be specified:
@op(config_schema={"name": str})
def hello_config(context):
"""
A configurable op definition.
"""
name = context.op_config["name"]
print(f"Hello, {name}!")
get_dagster_logger().info(f"Hello from logger: {name}!")
When executing this graph, the configuration also must be specified. Details are found here: https://docs.dagster.io/concepts/configuration/config-schema. One easy way to specify the configuration is directly in dagit. In fact, dagit allows scaffolding (automatically generating) a suitable structure of the required configuration values. Furthermore, matching types are ensured directly in the configuration. This means: In case a number is expected, dagit will warn about a type incompatibility when a text is specified instead.
The logs will now directly contain the hello message for the configured name.
Give it another try and supply the required configuration using the scaffolding mechanism in the dagit UI:
ops:
hello_config:
config:
name: "Georg"
Further material:
- https://docs.dagster.io/tutorial/advanced-tutorial/configuring-ops
- https://docs.dagster.io/concepts/configuration/config-schema
Multiple possibilities exist to supply the configuration (CLI, JSON, YAML fragments in the Dagit UI, default configuration in python).
schema validation
Data frames from pandas and other tools are frequently used when processing data. In the particular case of pandas - which is used very frequently - tools like Pandera have been created to validate the data.
Dagster offers an excellent integration here. It is demonstrated in the stocks_job.
This example is based on https://docs.dagster.io/integrations/pandera#using-dagster-with-pandera.
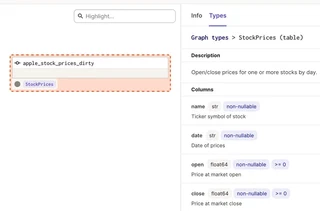
class StockPrices(pa.SchemaModel):
"""Open/close prices for one or more stocks by day."""
name: Series[str] = pa.Field(description="Ticker symbol of stock")
date: Series[str] = pa.Field(description="Date of prices")
open: Series[float] = pa.Field(ge=0, description="Price at market open")
close: Series[float] = pa.Field(ge=0, description="Price at market close")
The data validation constraints are specified with the usual pandera functionality.
By applying the pandera_schema_to_dagster_type function, a dagster type can be created.
This allows to:
- directly in the user interface show the specific expected type information of the dataframe
- and apply the desired validation rules (i.e. perhaps fail the job if the data is not matching the expectations)
@op(out=Out(dagster_type=pandera_schema_to_dagster_type(StockPrices)))
def apple_stock_prices_dirty():
prices = pd.DataFrame(APPLE_STOCK_PRICES)
i = random.choice(prices.index)
prices.loc[i, "open"] = pd.NA
prices.loc[i, "close"] = pd.NA
return prices
The data was deliberately destroyed for demonstration purposes and NULL values were inserted. As expected, Pandera validates the data and throws an error as the NULL values are not allowed with this schema definition.
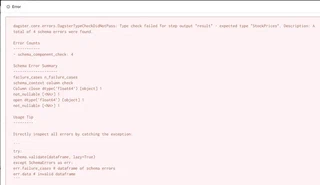
summary
Dagster can quickly bring visibility in the dependency of the various python functions and their inputs and outputs required to make the use case run.
Furthermore, it comes with observability capabilities and supports configurable jobs.
Tools like Pandera easily integrate to capture details about data quality. They can stop the execution of a job when incompatible data is detected.
