Comparing SQL-based streaming approaches
overview
An increasing number of companies use streaming when processing data. A streaming ledger like Apache Kafka often acts as the backbone. One of the core functions is to buffer the events. This buffer allows a slower downstream consumer to keep up with processing bursty workloads or increase its processing capacity by stopping and restarting with more parallelism. Furthermore, the ledger allows flexibly replaying the log when an additional subscriber needs access to the data. Thus, it allows to add new subscribers and keep them in sync.
However, often, the ledger does not store all the data. It is separated into a real-time and long-term storage system (blob storage).
For analytical data integration, perhaps using a streaming-friendly format like delta lake can be a perfect and cheap solution.
Nevertheless, it will add some latency and thus only qualifies for a near real-time data warehousing (analytics) approach.
It could unify the near-real-time and long-term storage layer for the ease of analytical purposes.
However, it would not result in an operational data application powering a core business process with minimal latency.
Instead, I want to explore not only an analytical - rather an operational (very low latency) data integration which consists of the following steps in order to create a real-time core streaming data model:
- a read (one or more) topic(s) from the streaming ledger
- arbitrary (stateful) computation
- (eventually) write the results back to the streaming ledger (so that other operational analytical processes can subscribe and react to events)
The following streaming engines will be compared:
- ksqlDB
- Spark structured streaming
- Flink
- Materialize
In this demonstration, I will focus on the SQL-(ish) APIs over the code-based ones. The idea is to demonstrate reading the events from kafka, performing some arbitrary computation and writing back to kafka.
I create this post to compare the various existing streaming tools and get a feeling for their pros and cons. The source code of the examples is available on github, though the explanatory part will be much more polished in this blog post.
setup instructions
To follow along with the eample, you need to have installed for your platform:
- JDK 8 or 11 and JAVA_HOME set up
- git
- miniconda
- docker
Then:
git clone https://github.com/geoHeil/streaming-example.git
cd streaming-example
# prepare mamba https://github.com/mamba-org/mamba
conda activate base
conda install -y -c conda-forge mamba
conda deactivate
make create_environment
conda activate streaming-example
docker-compose pull
cd dbtsql
dbt deps
cd ..
Furthermore, you need to have available:
Spark: Download the latest stable release (currently 3.2.1). Then unzip Spark.
Flink: Download the latest stable release (currently 1.14.4). Then unzip Flink.
- Ensure to set the
rest.port: 8089for the configuration:conf/flink-conf.yamlis set. This specifies a different port for the UI of flink - as some of the containers already take the default port. - get the additional jars to allow for Avro + kafka + Confluent schema registry connectivity:
cd flink-1.14.4/ wget https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.12/1.14.4/flink-sql-connector-kafka_2.12-1.14.4.jar -P lib/ wget https://repo1.maven.org/maven2/org/apache/flink/flink-sql-avro-confluent-registry/1.14.4/flink-sql-avro-confluent-registry-1.14.4.jar -P lib/- Ensure to set the
Materialize (0.24.0):
curl -L https://binaries.materialize.com/materialized-v0.26.0-$(uname -m)-unknown-linux-gnu.tar.gz | sudo tar -xzC /usr/local --strip-components=1. Unpack into a folder of your choice.
Perhaps consider adding them to the path for easier access.
For the next steps, I assume that you already have all the services running in their docker containers and the ports are all available on localhost:
docker-compose up
Some essential ports which should be available after some minutes:
- Schema Registry: localhost:8081
- Control Center: localhost:9021
If you have any problems: the official Confluent quickstart guide is a good resource when looking for answers.
Flink and Spark both currently work well with JDK 8 or 11. The most recent LTS (17) is not yet fully supported.
KafkaEsque is a great Kafka Development GUI. The latest release, however, requires a Java 17 installation or newer. I suggest jenv or perhaps docker to isolate the various JDK instances on your machine. On OsX the KafkaEsque binary might fail to start. To fix it, follow the instructions in the official readme:
xattr -rd com.apple.quarantine kafkaesque-2.1.0.dmg
In case you prefer another visual tool for kafka, perhaps the JetBrains BigData Tools are for you.
why streaming?
Traditional (analytical) batch data pipelines often hold delayed data (non-real-time data - by definition). Furthermore, handling late-arriving data can become very tricky as custom logic is required.
Traditional operational data integration in core business processes requires domain-specific microservices/applications - often with $n^2$ point-to-point integrations (= a big mess), where $n$ refers to the number of applications which need to be integrated.
In recent years the streaming semantics, which allows to deal with stateful operations nicely and at least ease these burdens, have flourished. Similar semantics would be beneficial for very low-latency operational integrations on a core streaming platform.
Core concepts for streaming data are:
- triggers: Trigger the streaming computation based on specific times i.e. every n minutes, once a micro-batch is finished or on specific conditions
- watermarking: There is a need to separate event-time and processing-time and allow for a maximum lateness of the data. Most streaming tools support this to have an explicit notion of handling late arriving data.
- processing guarantees: At most once, at least once and exactly once. Often exactly-once processing is desirable but costly to achieve, particularly when integrating various (segregated) systems.
The good thing about streaming tools is that these core concepts are first-class citizens and do not require hand-rolled custom (error-prone) logic. Most streaming tools are implemented as a distributed system for fault tolerance and scalability. This results in some specific attributes:
- shuffle and non-determinism: Data transfer between the various compute nodes is slow (slower than any in-process handling). Therefore it should be avoided (when possible). The network packages transferring the data are not guaranteed to arrive in any particular order. When data needs to be exchanged it is named a shuffle operation.
- partitions and temporal order: Scalability is achieved using the map-reduce-paradigm. For a specific key arbitrary functions are applied. All the data for a key resides in a single partition. The system can scale to many keys on many partitions which are distributed to a large number of compute nodes. Usually, the order of messages can only be guaranteed per key (and not globally).
practical example
Now off to a practical example comparing the basics of ksqlDB, Spark structured streaming, Flink and Materialize.
creation of dummy data
The official Confluent example is a great start. But instead, I want to show how to use a custom Avro schema (not one of the ones provided by default). For this, I follow the steps outlined by thecodinginterface and reused his example schema:
{
"type": "record",
"name": "commercialrating",
"fields": [
{
"name": "brand",
"type": {
"type": "string",
"arg.properties": {
"options": ["Acme", "Globex"]
}
}
},
{
"name": "duration",
"type": {
"type": "int",
"arg.properties": {
"options": [30, 45, 60]
}
}
},
{
"name": "rating",
"type": {
"type": "int",
"arg.properties": {
"range": { "min": 1, "max": 5 }
}
}
}
]
}
We are looking at ad-impressions for specific companies for a duration with a rating. To generate dummy data we can use the UI or the API. Let`s start by taking a look at the UI-based approach: Go to the Confluent Control Center on: localhost:9021 and select the controlcenter.cluster cluster.
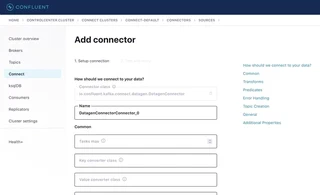
As you can observe all the neccessary fields can be entered in the UI.
Secondly, let`s use the REST API to POST the user-defined schema from above to the kafka connect data generator. For this you need to set some additional properties (like how many data points should be generated).
Let`s create two dummy data sets. One serialized as JSON, the second one serialized as Avro - where the schema is stored in the Confluent schema registry:
JSON:
{
"name": "datagen-commercials-json",
"config": {
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"kafka.topic": "commercials_json",
"schema.string": "{\"type\":\"record\",\"name\":\"commercialrating\",\"fields\":[{\"name\":\"brand\",\"type\":{\"type\": \"string\",\"arg.properties\":{\"options\":[\"Acme\",\"Globex\"]}}},{\"name\":\"duration\",\"type\":{\"type\":\"int\",\"arg.properties\":{\"options\": [30, 45, 60]}}},{\"name\":\"rating\",\"type\":{\"type\":\"int\",\"arg.properties\":{\"range\":{\"min\":1,\"max\":5}}}}]}",
"schema.keyfield": "brand",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"max.interval": 1000,
"iterations": 1000,
"tasks.max": "1"
}
}
Avro with the Confluent schema registry:
{
"name": "datagen-commercials-avro",
"config": {
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"kafka.topic": "commercials_avro",
"schema.string": "{\"type\":\"record\",\"name\":\"commercialrating\",\"fields\":[{\"name\":\"brand\",\"type\":{\"type\": \"string\",\"arg.properties\":{\"options\":[\"Acme\",\"Globex\"]}}},{\"name\":\"duration\",\"type\":{\"type\":\"int\",\"arg.properties\":{\"options\": [30, 45, 60]}}},{\"name\":\"rating\",\"type\":{\"type\":\"int\",\"arg.properties\":{\"range\":{\"min\":1,\"max\":5}}}}]}",
"schema.keyfield": "brand",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter.schemas.enable": "false",
"max.interval": 1000,
"iterations": 1000,
"tasks.max": "1"
}
}
To switch the serialization format only the serializer changes from:
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
to:
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
when switching from JSON to Avro (for the message value). A similar change could also perhaps be applied to the key.
Assuming you have stored this API request JSON snippet as a file named: datagen-json-commercials-config.json you can now interact with the REST API using:
curl -X POST -H "Content-Type: application/json" -d @datagen-json-commercials-config.json http://localhost:8083/connectors | jq
When switching back into the UI you can now observe the running connector:
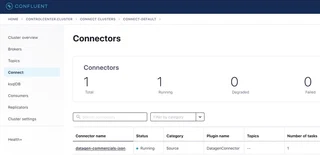
You can check the status from the command line:
curl http://localhost:8083/connectors/datagen-commercials-json/status | jq
curl http://localhost:8083/connectors/datagen-commercials-avro/status | jq
As a sanity check you can consume some records:
docker exec -it broker kafka-console-consumer --bootstrap-server localhost:9092 \
--topic commercials_json --property print.key=true
docker exec -it broker kafka-console-consumer --bootstrap-server localhost:9092 \
--topic commercials_avro --property print.key=true
The generated events (messages) are also available in the UI of Confluent Control Center:
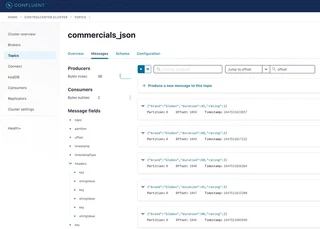
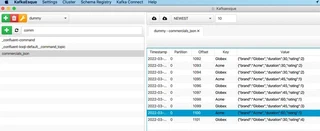
In similar fashion KafkaEsque might be used to view the messages. But KafkaEsque needs to be configured first to view the kafka records:
Then the results are visible here:
A further promising Kafka management UI is: https://github.com/redpanda-data/kowl.
To stop the connector simply either delete it in the UI of the control center or use the REST API:
curl -X DELETE http://localhost:8083/connectors/datagen-commercials-json
curl -X DELETE http://localhost:8083/connectors/datagen-commercials-avro
In case, the AVRO format is used for serialization, the schema registry will showcase the schema respectively:
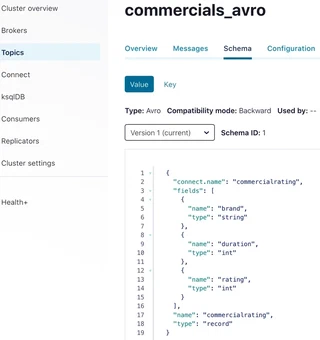
analytics
In the following section, I will present how to interact with the data stored in the commercials_avro topic using:
- KSQL in version of Confluent Platform 7.0.1
- Spark Structured Streaming version 3.2.1
- Flink (SQL like table API) verfsion 1.14.4
- Materialize (real-time database based on Postgres SQL API) version 0.24.0
All tools offer the possibility for exactly-once processing for a data pipeline with reads from kafka and writes to kafka (after performing a computation). But this is usually not the default mode and needs to be enabled explicitly.
ksqlDB
ksqlDB is a simple add-on to enable SQL-based stream processing directly on top of kafka.
The three core concepts of ksqlDB are:
- topic
- the original Kafka topic holding the data
- stream
- unbounded: Storing a never-ending continuous flow of data
- immutable: New event records are append-only for the log (kafka). No modifications of existing data are performed
- table
- bounded: Represents a snapshot of the stream at a time, and therefore the temporal limits are well defined.
- mutable: Any new data(
<Key, Value>pair) that comes in is appended to the current table if the table does not have an existing entry with the same key. Otherwise, the existing record is mutated to have the latest value for that key.
There is a duality between streams and tables (stream as event log composing the table, table as the snapshot point-in-time version of a stream)
To learn more about ksqlDB I recommend the documentation found in:
- https://blog.knoldus.com/ksql-streams-and-tables/
- https://developer.confluent.io/learn-kafka/ksqldb/streams-and-tables/
- https://www.confluent.io/blog/kafka-streams-tables-part-3-event-processing-fundamentals/
- https://docs.ksqldb.io/en/latest/operate-and-deploy/schema-registry-integration/
The initial step when interacting with ksqlDB is to register a stream from an existing topic in kafka:
CREATE OR REPLACE STREAM metrics_brand_stream
WITH (
KAFKA_TOPIC='commercials_avro',
VALUE_FORMAT='AVRO'
);
When submitting the query, ensure to decide if you want to start from:
- latest: only new records will be processed
- earliest: all existing records are processed
The next step is to define a continuously running query that is materialized as a table. Two types of queries are available (https://docs.ksqldb.io/en/latest/concepts/queries):
- push: client subscribes to a result as it changes in real-time
- pull: emits refinements to a stream or materialized table, which enables reacting to new information in real-time
A simple aggregation query can be prototyped (from the CLI or the ControlCenter UI):
SELECT brand,
COUNT(*) AS cnt
FROM metrics_brand_stream
GROUP BY brand
EMIT CHANGES;
and materialized as a table:
CREATE OR REPLACE TABLE metrics_per_brand AS
SELECT brand,
COUNT(*) AS cnt,
AVG(duration) AS duration_mean,
AVG(rating) AS rating_mean
FROM metrics_brand_stream
GROUP BY brand
EMIT CHANGES;
The table will emit changes automatically to any downstream consumer who subscribes to the changes.
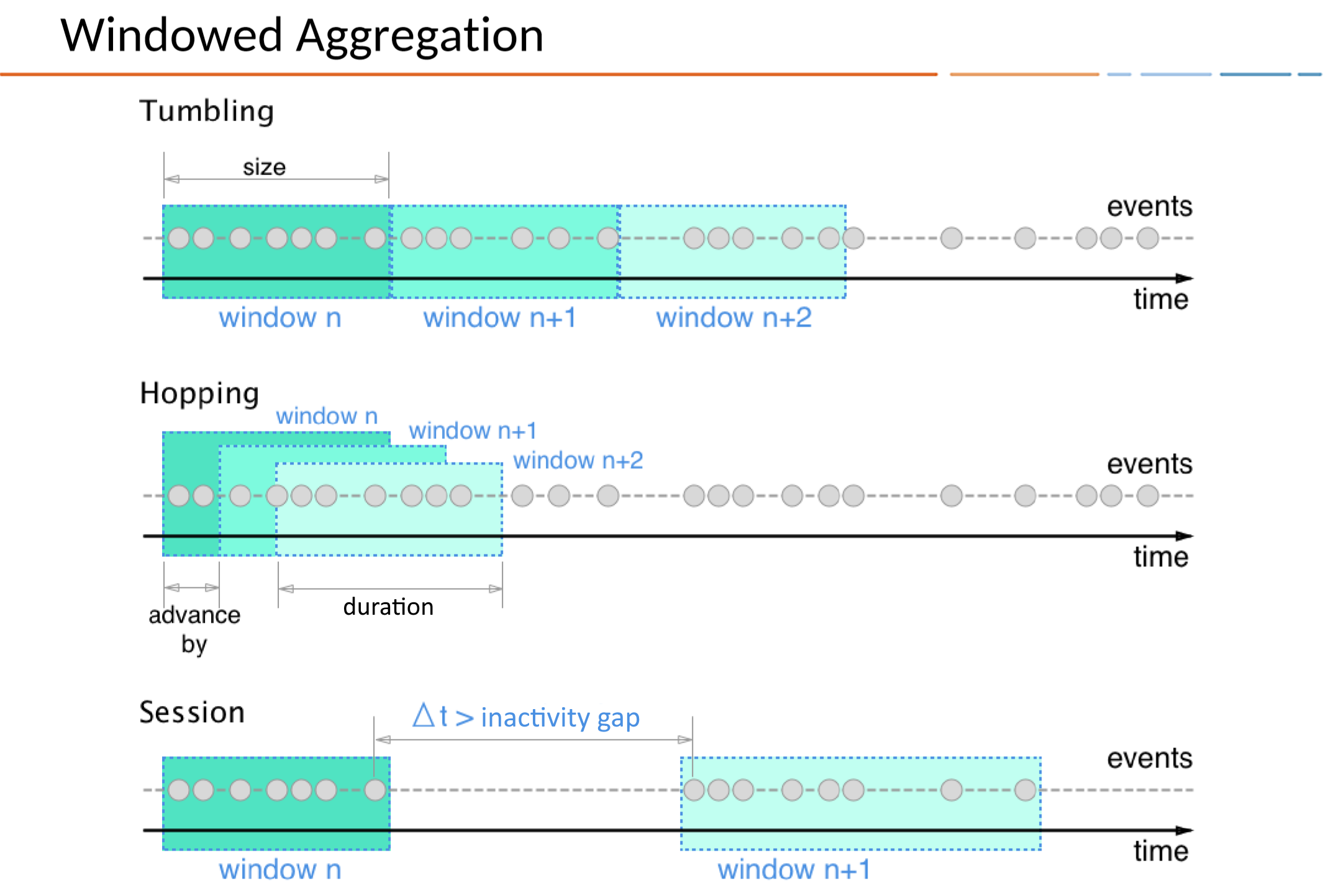
Streams rarely are aggregated globally. Often (time) windows are used. Various window types https://docs.ksqldb.io/en/latest/concepts/time-and-windows-in-ksqldb-queries/ (tumbling, hopping, session) are supported by ksqlDB and are explained here:
- tumbling: Fixed-duration, non-overlapping, gap-less windows
- hopping: Fixed-duration, overlapping windows
- sliding: (https://github.com/confluentinc/ksql/issues/6873) apparently not yet fully supported in ksqlDB (but in some of the other engines we will look at later though) https://stackoverflow.com/questions/43188997/hopping-vs-sliding-window concetizes the difference between hopping and slding windows. (both sound quite similar)
- custom session window: Dynamically-sized, non-overlapping, data-driven windows
Perhaps specific brands are of interest which are bought frequently:
CREATE OR REPLACE TABLE metrics_per_brand_windowed AS
SELECT BRAND, count(*)
FROM metrics_brand_stream
WINDOW TUMBLING (SIZE 5 SECONDS)
GROUP BY BRAND
HAVING count(*) > 3;
Exactly once handling can be enabled by changing the configuration: https://docs.ksqldb.io/en/latest/operate-and-deploy/exactly-once-semantics/
SET 'processing.guarantee' = 'exactly_once';
Do not forget to set consumer isolation level for the kafka transactions or any consumers of the topic.
Spark structured streaming
Spark is a generic (big) data analytics tool that also supports a streaming execution mode. Originally Spark was built for batch processing. Therefore, today, Spark still does follow a minibatch streaming model. The first step for Spark is to add the required jars to enable kafka & schema registry connectivity. The following additional packages are required:
- https://github.com/AbsaOSS/ABRiS for making Spark play nice with Avro and schema registries
- default additional packages for kafka & Avro support
spark-shell --master 'local[4]'\
--repositories https://packages.confluent.io/maven \
--packages org.apache.spark:spark-avro_2.12:3.2.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.1,za.co.absa:abris_2.12:6.2.0 \
--conf spark.sql.shuffle.partitions=4
In case you are using Spark behind a corporate proxy use:
- https://stackoverflow.com/questions/36676395/how-to-resolve-external-packages-with-spark-shell-when-behind-a-corporate-proxy
- https://godatadriven.com/blog/spark-packages-from-a-password-protected-repository/
To override the default ivy resolver with your corporate artifact store.
The next step is to register a kafka-based data source in Spark.
Spark allows for batch and stream processing.
In fact, switching the read to the readStream function streaming can be prototyped quite fast using the batch functionalities - before later turning the query into a long-running streaming job.
readStream into the read function.val df = spark
.read
//.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
//.option("startingOffsets", "earliest") // start from the beginning each time
.option("subscribe", "commercials_avro")
.load()
df.printSchema
root
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)
Notice how the key and value columns are both binary fields that contain the Avro record for the key and value of the event.
To parse the Avro (using the schema stored in the schema registry) use the abris library:
import za.co.absa.abris.config.AbrisConfig
import za.co.absa.abris.avro.functions.from_avro
val abrisConfig = AbrisConfig
.fromConfluentAvro
.downloadReaderSchemaByLatestVersion
.andTopicNameStrategy("commercials_avro")
.usingSchemaRegistry("http://localhost:8081")
val deserialized = df.select(from_avro(col("value"), abrisConfig) as 'data).select("data.*")
deserialized.printSchema
root
|-- brand: string (nullable = true)
|-- duration: integer (nullable = true)
|-- rating: integer (nullable = true)
Now the columns for brand, duration and rating are available. Queries can easily be prototyped in the non-streaming mode:
deserialized.groupBy("data.brand").count.show
Let’s switch the reading mode over to streaming by turning the read into the readStream:
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("startingOffsets", "earliest") // start from the beginning each time
.option("subscribe", "commercials_avro")
.load()
val abrisConfig = AbrisConfig
.fromConfluentAvro
.downloadReaderSchemaByLatestVersion
.andTopicNameStrategy("commercials_avro")
.usingSchemaRegistry("http://localhost:8081")
val deserialized = df.withColumn("data", from_avro(col("value"), abrisConfig))
deserialized.printSchema
root
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)
|-- data: struct (nullable = true)
| |-- brand: string (nullable = false)
| |-- duration: integer (nullable = false)
| |-- rating: integer (nullable = false)
val query = deserialized.groupBy("data.brand").count.writeStream
.outputMode("complete")
.format("console")
.start()
// to stop query in interactive shell and continue development
// query.stop
For the streaming query the simple show function no longer works.
Instead a sink - for eample the console output sink is required.
Streams can be processed in various output modes (append, complete, update).
Not all the sinks support all output modes for all query types.
The output modes https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#output-modes
- append (default): new rows are added
- complete: final aggregation result
- update: only updates are pushed on
When the dummy data source is pushing more data to the topic - the streaming query will re-execute the aggregation. Here, you can see two examples of the outputted batch updates:
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| brand|count|
+------+-----+
|Globex| 694|
| Acme| 703|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| brand|count|
+------+-----+
|Globex| 695|
| Acme| 703|
+------+-----+
Whilst a long-running structured streaming query is executing make sure to look at the monitoring part of Sparks UI: http://localhost:4040/StreamingQuery In particular you can see the query input and processing rate and can observe if there is any backlog (the batch duration is increasing over the minibatch processing time).
Do not forget to fine-tune Spark`s configuration! Even for batch processing Spark has a lot of knobs you can but also have to fine-tune. In particular, for streaming look at the default shuffle parallelism. 200 partitions might be much to high for the amount of data you are processing (and delaying the query).
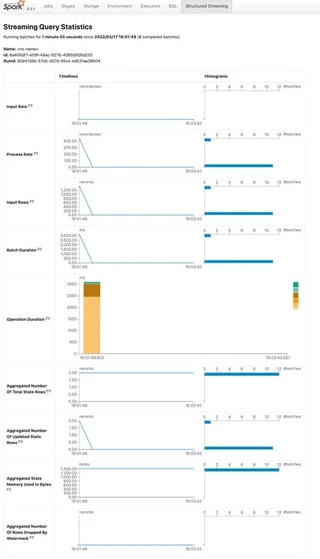
Now back to the windowed streaming query and windowing. In both modes (batch and streaming) Spark supports window-based aggregations.
Here in this example, the withWatermark defines a watermark for a maximum lateness tolerance of the data of 10 minutes.
See: https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#handling-event-time-and-late-data for details.
// non streaming
deserialized.select($"timestamp", $"data.*")
.withWatermark("timestamp", "10 minutes")
.groupBy(window($"timestamp", "5 seconds"), $"brand").count
.filter($"count" > 3)
.show(false)
// streaming
val query = deserialized.select($"timestamp", $"data.*")
.withWatermark("timestamp", "10 minutes")
.groupBy(window($"timestamp", "5 seconds"), $"brand").count
.filter($"count" > 3)
.writeStream
.outputMode("complete")
.format("console")
.start()
query.stop
The previous examples only used the console sink. The next step is also to write the data back to kafka. The output schema needs to be registered with the schema registry. For each key (brand) the metrics (average rating and average duration) are stored. For consistency reasons (in a setup with multiple partitions) the key needs to be present (brand) to ensure that all records to that key go into the same kafka partition (temporal ordering).
Further details can be found in the documentation: https://github.com/AbsaOSS/ABRiS/blob/master/documentation/confluent-avro-documentation.md
import za.co.absa.abris.avro.parsing.utils.AvroSchemaUtils
import za.co.absa.abris.avro.read.confluent.SchemaManagerFactory
import org.apache.avro.Schema
import za.co.absa.abris.avro.read.confluent.SchemaManager
import za.co.absa.abris.avro.registry.SchemaSubject
import za.co.absa.abris.avro.functions.to_avro
import org.apache.spark.sql._
import za.co.absa.abris.config.ToAvroConfig
// generate schema for all columns in a dataframe
val valueSchema = AvroSchemaUtils.toAvroSchema(aggedDf)
val keySchema = AvroSchemaUtils.toAvroSchema(aggedDf.select($"brand".alias("key_brand")), "key_brand")
val schemaRegistryClientConfig = Map(AbrisConfig.SCHEMA_REGISTRY_URL -> "http://localhost:8081")
val t = "metrics_per_brand_spark"
val schemaManager = SchemaManagerFactory.create(schemaRegistryClientConfig)
// register schema with topic name strategy
def registerSchema1(schemaKey: Schema, schemaValue: Schema, schemaManager: SchemaManager, schemaName:String): Int = {
schemaManager.register(SchemaSubject.usingTopicNameStrategy(schemaName, true), schemaKey)
schemaManager.register(SchemaSubject.usingTopicNameStrategy(schemaName, false), schemaValue)
}
registerSchema1(keySchema, valueSchema, schemaManager, t)
When now writing the data back to kafka it is crucial that a column named key is present.
Two AbrisConfig objects (one for the key and one for the value) are needed.
Specifying the key so that all messages on the same key go to the same partition is very important for proper ordering of message processing if you will have multiple consumers in a consumer group on a topic.
Without a key, two messages on the same key could go to different partitions and be processed by different consumers in the group out of order. https://stackoverflow.com/questions/40872520/whats-the-purpose-of-kafkas-key-value-pair-based-messaging
val toAvroConfig4 = AbrisConfig
.toConfluentAvro
.downloadSchemaByLatestVersion
.andTopicNameStrategy(t)
.usingSchemaRegistry("http://localhost:8081")
val toAvroConfig4Key = AbrisConfig
.toConfluentAvro
.downloadSchemaByLatestVersion
.andTopicNameStrategy(t, isKey = true)
.usingSchemaRegistry("http://localhost:8081")
def writeDfToAvro(keyAvroConfig: ToAvroConfig, toAvroConfig: ToAvroConfig)(dataFrame:DataFrame) = {
val availableCols = dataFrame.columns//.drop("brand").columns
val allColumns = struct(availableCols.head, availableCols.tail: _*)
dataFrame.select(to_avro($"brand", keyAvroConfig).alias("key"), to_avro(allColumns, toAvroConfig) as 'value)
}
val aggedAsAvro = aggedDf.transform(writeDfToAvro(toAvroConfig4Key, toAvroConfig4))
aggedAsAvro.printSchema
root
|-- key_brand: binary (nullable = true)
|-- value: binary (nullable = false)
aggedAsAvro.write
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("topic", t).save()
Compared to ksqlDB this already requires much more (custom code). However, this is only the case for the OSS version of Spark. The commercial (Databricks) offering: https://docs.microsoft.com/en-us/azure/databricks/spark/latest/structured-streaming/avro-dataframe offers a SQL-ish-more-native function for interacting with the schema registry (straight from the linkq-style DSL). However, sadly (https://github.com/apache/spark/pull/31771) contributions to OSS Spark in this direction never fully materialized. AWS even goes one step further in their commercial offering of Spark and adds a DynamicFrame dataframe like functionality to support a schema that changes over time.
The following is the schema ABRiS auto-generated from the dataframe’s StructTypes and stored in the schema registry:
{
"fields": [
{
"name": "brand",
"type": [
"string",
"null"
]
},
{
"name": "rating_mean",
"type": [
"double",
"null"
]
},
{
"name": "duration_mean",
"type": [
"double",
"null"
]
}
],
"name": "topLevelRecord",
"type": "record"
}
Again the data is available in kafka for downstream consumption of other services. However, this time, the brand is stored twice (once in the key) and once in the value. This could be changed to store the brand only once as an improvement.
Further great examples and documentation about structured streaming can be found:
- https://docs.databricks.com/spark/latest/structured-streaming/demo-notebooks.html#structured-streaming-demo-scala-notebook
- https://medium.com/datapebbles/kafka-to-spark-structured-streaming-with-exactly-once-semantics-35e4281525fc
- https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-streaming-exactly-once
- https://sbanerjee01.medium.com/exactly-once-processing-with-spark-structured-streaming-f2a78f45a76a
Only with the very recent version of Spark (3.2.x) the scalable state backend implemented in RocksDB was open-sourced. RocksDB serves as a state backend for large scale streaming queries with big amount of state.
Exactly once processing semantics can be achieved like in ksqlDB, but are more complex:
- checkpoints to a persistent volume (for the write-ahead log) are required
- kafka`s transactional capabilities may need to be used (like also for ksqlDB).
In case you are only interested in a very cheap analytical near-realtime (like approx 2 minutes delay, certainly » 1 second) processing of the data an efficient Rust-based kafka consumer which writes delta tables might be the right choice for you. To easily allow for efficient scans and also to avoid having to query two systems (streaming and long-term storage) delta tables (with compaction enabled) might be much cheaper and easier to use when a bit more latency can be tolerated after initially sinking the data over from kafka to a long term storage solution (using kafka only as a buffer) and not as a very low latency operational data integration for a core streaming model. https://www.upsolver.com/blog/blog-apache-kafka-and-data-lake brings up more arguments towards such an architecture in case of an anlytical only setup.
flink
Flink is a true streaming engine. For an introduction and setup instructions refer to:
- https://nightlies.apache.org/flink/flink-docs-release-1.14//docs/try-flink/local_installation/
- https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/formats/avro-confluent/
The setup of flink was described above - but as I had some problems initially to get it right I will detail the setup again.
The 2.12 version of Scala is used in the following example.
The sql-* uber jars are required and not the very prominently displayed maven coordinates! When not using a build tool this is super important. Otherwise you need to specify many transitive dependencies which is cumbersome and error-prone.
The jars for avro, kafka and schema registry are required:
cd flink-1.14.4/
wget https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.12/1.14.4/flink-sql-connector-kafka_2.12-1.14.4.jar -P lib/
wget https://repo1.maven.org/maven2/org/apache/flink/flink-sql-avro-confluent-registry/1.14.4/flink-sql-avro-confluent-registry-1.14.4.jar -P lib/
As all the kafka and other docker containers have a clashing port range with flink’s default settings, change:
vi conf/flink-conf.yaml
# and set:
rest.port: 8089
Flink can then be started with the start-cluster.sh script.
Secondly, a SQL client is brought up.
./bin/start-cluster.sh local
ps aux | grep flink
The statement above will start a single slot/CPU core for flink. If more slots are required, increase the number of task managers:
./bin/taskmanager.sh start
./bin/sql-client.sh
# to cleanup later:
# ./bin/taskmanager.sh stop-all
# ./bin/stop-cluster.sh
Flink as a great UI which should by now be available here: http://localhost:8089/
In case it is not showing up - check the logs which are created in the log folder for any exception describing the problem.
Whilst exploring flink for this blog post I realized that the scala shell was moved out of the core flink project in case of 2.12:
- the current destination: https://github.com/zjffdu/flink-scala-shell
- decision why to move: https://lists.apache.org/thread/pojsrrdckjwow5186nd7hn9y5j9t29ov
- Zeppelin can serve as an interactive interpreter: https://zeppelin.apache.org/docs/latest/interpreter/flink.html to replace the REPL
Further documentation for flinks components is available:
- the SQL client https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/sqlclient/
- kafka connector https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/kafka/
- confluent schema registry and Avro https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/formats/avro-confluent/
- the upsert-kafka connector https://nightlies.apache.org/flink/flink-docs-master/docs/connectors/table/upsert-kafka/
- watermarks https://nightlies.apache.org/flink/flink-docs-master/docs/dev/datastream/event-time/generating_watermarks/
Flink`s SQL capabilities are more native, like the ones provided by ksqlDB, even tough flink is just like Spark a compute engine separated from storage. All the required functions can be accessed directly from SQL.
However, for any complex streaming job, it is probably still true, particularly regarding operator state migration, that a SQL-based job might run into problems when upgrading flink (as the graph of the operators might change). Therefore depending on the complexity a JVM-based flink job might be more desirable.
The raw input topic in kafka needs to be registered with flink first. If desired, the time field from kafka can directly be used for watermarking. Furthermore, no additional custom code is required for interaction with the schema registry - even for the OSS version, this is only fluent SQL.
-- DROP TABLE metrics_brand_stream;
CREATE TABLE metrics_brand_stream (
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',
--WATERMARK FOR event_time AS event_time - INTERVAL '10' MINUTE,
`partition` BIGINT METADATA VIRTUAL,
`offset` BIGINT METADATA VIRTUAL,
brand string,
duration int,
rating int
) WITH (
'connector' = 'kafka',
'topic' = 'commercials_avro',
'scan.startup.mode' = 'earliest-offset',
'format' = 'avro-confluent',
'avro-confluent.schema-registry.url' = 'http://localhost:8081/',
'properties.group.id' = 'flink-test-001',
'properties.bootstrap.servers' = 'localhost:9092'
);
Now the stream can be explored using the full power of SQL.
Interestingly, I observe that a manual type cast seems to be necessary for the AVG operation not to truncate the results back to its int values.
So far, I do not have a good explanation for why this happens - as any other SQL engine I have interacted with so far was automatically returning a double value for a mean computation.
SELECT * FROM metrics_brand_stream;
SELECT AVG(duration) AS duration_mean, AVG(CAST(rating AS DOUBLE)) AS rating_mean FROM metrics_brand_stream;
-- !! Manual type cast needed to get the expected result!
SELECT AVG(duration) AS duration_mean, AVG(rating) AS rating_mean FROM ms;
SELECT brand,
COUNT(*) AS cnt,
AVG(duration) AS duration_mean,
AVG(rating) AS rating_mean
FROM metrics_brand_stream
GROUP BY brand;
Unlike Spark the schema for the output needs to be manually declared in SQL.
For both the key and the value entries are necessary.
-- DROP TABLE metrics_per_brand;
CREATE TABLE metrics_per_brand (
brand string,
cnt BIGINT,
duration_mean DOUBLE,
rating_mean DOUBLE
,PRIMARY KEY (brand) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'metrics_per_brand_flink',
'properties.group.id' = 'flink-test-001',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'avro-confluent',
'key.avro-confluent.schema-registry.subject' = 'metrics_per_brand_flink-key',
'key.avro-confluent.schema-registry.url' = 'http://localhost:8081/',
'value.format' = 'avro-confluent',
'value.avro-confluent.schema-registry.subject' = 'metrics_per_brand_flink-value',
'value.avro-confluent.schema-registry.url' = 'http://localhost:8081/'
);
Lastly, a simple INSERT clause can be triggered from SQL to start the long-running streaming query:
INSERT INTO metrics_per_brand
SELECT brand,
COUNT(*) AS cnt,
AVG(duration) AS duration_mean,
AVG(rating) AS rating_mean
FROM metrics_brand_stream
GROUP BY brand;
select * from country_target;
Flink allows for exactly-once processing with similar configuration changes as the other tools before (https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/fault-tolerance/checkpointing/#enabling-and-configuring-checkpointing). Namely a checkpoint directory needs to be set up and the kafka transactions need to be used for downstream consumers. Flink allows to customize some settings with regards to checkpointing straight from SQL
SET 'state.checkpoints.dir' = 'hdfs:///my/streaming_app/checkpoints/';
SET 'execution.checkpointing.mode' = 'EXACTLY_ONCE';
SET 'execution.checkpointing.interval' = '30min';
SET 'execution.checkpointing.min-pause' = '20min';
SET 'execution.checkpointing.max-concurrent-checkpoints' = '1';
SET 'execution.checkpointing.prefer-checkpoint-for-recovery' = 'true';
Just as I before linked a commercial example for Spark from Databricks, Ververica provides similar examples for flink: https://www.ververica.com/blog/ververica-platform-2.3-getting-started-with-flink-sql-on-ververica-platform
A fully-fledged flink program probably should include:
- unit tests
- perhaps custom functionalities for triggers
- additional libraries for specific tasks i.e. geospatial tasks
such a more realistic job should be constructed using a build tool like Gradle and the Java or Scala API of flink.
Nonetheless, for simple (traditional) ETL-style transformations, the SQL DSL of flink (including CEP - MATCH RECOGNIZE clause) might already be all what you need.
https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/sql/queries/match_recognize.
But when handling multiple event types in a single topic custom code is required.
new streaming databases
The old batch world has been shaken by a storm around the modern data stack where in particular DBT plays a key role. The main benefit of DBT is an engineering mindest to SQL:
- testing
- lineage of dependencies
- templating (DRY) code reuse
But the so far mainstream adapters of DBT do not allow for streaming. Interestingly, the current top dogs in streaming (flink and Spark) do not offer a DBT integration yet. I think in the examples above you might already have been able to get a glimpse about the complexity of the established streaming solutions.
But new streaming databases are up-and-coming:
- https://materialize.com is built on top of https://github.com/TimelyDataflow/timely-dataflow. By using the API of postgres it is from the first second already familiar to analysts. Computations are expressed as dataflows.
- https://rockset.com offers real-time indexing of every field for fast queries
Both choices integrate well with DBT - and thus are friendly for analysts.
In the following section I will demonstryte first how to work with materialize (naively in SQL). Then in a second step show how to use DBT to automate the SQL transformations.
Start materialize in one terminal. The example here assumes you have added the binary to the path.
materialized --workers=1
In another terminal connect to materialize using the standard psql client:
psql -U materialize -h localhost -p 6875 materialize
Then register the source topic from kafka in materialize:
-- DROP SOURCE metrics_brand_stream;
CREATE MATERIALIZED SOURCE metrics_brand_stream
FROM KAFKA BROKER 'localhost:9092' TOPIC 'commercials_avro'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'http://localhost:8081'
INCLUDE PARTITION, OFFSET, TIMESTAMP AS ts
ENVELOPE NONE;
From now one you can directly experiment with the full power of postgresql with the data:
SELECT * FROM metrics_brand_stream;
SELECT brand,
COUNT(*) AS cnt,
AVG(duration) AS duration_mean,
AVG(rating) AS rating_mean
FROM metrics_brand_stream_m
GROUP BY brand;
You can explore the created sources by:
SHOW SOURCES;
SHOW CREATE SOURCE metrics_brand_stream;
SHOW COLUMNS IN metrics_brand_stream;
Then let`s continue and create a materialized view which stores the result of the ral-time query:
CREATE MATERIALIZED VIEW metrics_per_brand_view AS
SELECT brand,
COUNT(*) AS cnt,
AVG(duration) AS duration_mean,
AVG(rating) AS rating_mean
FROM metrics_brand_stream
GROUP BY brand;
Finally, when writing the data back to kafka you need to create a sink:
CREATE SINK metrics_per_brand
FROM metrics_per_brand_view
INTO KAFKA BROKER 'localhost:9092' TOPIC 'metrics_per_brand_materialize'
KEY (brand)
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'http://localhost:8081';
Exactly once processing guarantees can be achieved by changing the configuration of the sink.
The example project for DBT and materialize is found here: https://github.com/geoHeil/streaming-example/tree/master/dbtsql/models/commercials. As explained at the beginning, you first need to set up the required conda dependencies.
DBT will tell you by executing dbt debug where it expects the profiles.yml to be placed.
It contains the configuration and credentials how to access the database.
conda activate materialize-demo
cd dbtsql
dbt debug --config-dir
vi /Users/<<your_user>>/.dbt/profiles.yml
Paste profile file from https://github.com/geoHeil/streaming-example/blob/master/dbtsql/profiles.yml.
Furthermore, by executing dbt-deps install the additional dbt packages:
dbt debug
dbt deps # install required dependencies
Now you are ready to define the models. I define a model for:
- source (kafka input topic with the dummy data used in all the examples)
- staging (column names and data types are validated)
- mart (cleaned transformation) for some business domain
- sink (outputted mart back to streaming ledger for downstream consumption of this mart)
When transforming the original SQL to DBT - illustrated here with the example of the source
CREATE MATERIALIZED SOURCE metrics_brand_stream
FROM KAFKA BROKER 'localhost:9092' TOPIC 'commercials_avro'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'http://localhost:8081'
INCLUDE PARTITION, OFFSET, TIMESTAMP AS ts
ENVELOPE NONE;
the SQL changes to:
{{ config(materialized='source') }}
{% set source_name %}
{{ mz_generate_name('rp_commercials_information') }}
{% endset %}
CREATE SOURCE {{ source_name }}
FROM KAFKA BROKER 'localhost:9092' TOPIC 'commercials_avro'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'http://localhost:8081'
INCLUDE PARTITION, OFFSET, TIMESTAMP AS ts
ENVELOPE NONE;
Namely: mz_generate_name generates a suitable name and config(materialized='source') selects how this SQL snippets will be materialized.
DBT parses the template and ensures that the variables are filled in correctly.
The real-time streaming materialized views can be set up by simply executing DBT once:
dbt run
Then (in the shell) where the psql client is connected to materialize:
SHOW SOURCES;
SHOW VIEWS;
you will observe the various catalog items which were created from DBT executing the SQL transformations.
Additionally, DBT is well suited to generate very useful documentation and to test the queries:
dbt docs generate
dbt docs serve
dbt test

Further examples for these new up-and-coming databases interacting with DBT:
- materialize:
- https://blog.getdbt.com/dbt-materialize-streaming-to-a-dbt-project-near-you/
- https://materialize.com/docs/guides/dbt
- https://github.com/MaterializeInc/mz-hack-day-2022
- https://devdojo.com/bobbyiliev/how-to-use-dbt-with-materialize-and-redpanda wich nicely adds in Metabase for visualization of the straming queries.
- https://github.com/MaterializeInc/ecommerce-demo
- https://github.com/joacoc/BlockchainTail
- rockset
summary
Streaming tools have set out to accelerate and simplify the processing of data by offering true time-contextual streaming semantics i.e. wehn dealing with late arriving data. The current generation of streaming tools is very complex to use in production. In particlar ksqlDB albeit its ease of use has some significant downsides (checkpointing, gobal shuffle).
In the following, I will create a brief overview of the streaming tools and their advantages and disadvantages:
ksqlDB
✅
- high availability (no checkpointing. Needs a non-failing standby replica)
- streaming only using SQL
- established community
- ease of use
❌
- SQL completeness
- DBT integration
- checkpointing https://www.jesse-anderson.com/2019/10/why-i-recommend-my-clients-not-use-ksql-and-kafka-streams/
- JVM, complexity, configuration (not a single binary)
Spark Structured Streaming
✅
- streaming only using SQL (only in commercial offerings like Databricks)
- SQL completeness (no global shuffle operation, groupings cannot handle multiple columns)
- established community
- checkpointing
❌
- high availability (yarn or kubernetes can restart the master node - but there will be some downtime)
- streaming only using SQL (not possible in OSS)
- DBT integration
- JVM, complexity, configuration (not a single binary)
- ease of use
Flink
✅
- high availability
- streaming only using SQL
- SQL completeness
- DBT integration
- established community
- checkpointing
- ease of use (playground)
❌
- JVM, complexity, configuration (not a single binary)
- ease of use (complex big jobs can grow quite complex)
Materialized
✅
- high availability
- streaming only using SQL
- SQL completeness
- DBT integration
- Single binary - no JVM, less complexity (no additional zookeeper nodes required)
- ease of use
❌
- (not yet an) established community
My recommendation is as follows:
- Be cautious with ksqlDB - it lacks some essential features.
- For an analytics only streaming setup, Spark structured streaming can be really interesting (and with delta-lake) also cheap and straightforward
- For any operational low-latency data application I would say only flink offers the right primitives
The new up-and-coming databases like materialize should be watched closely, however. They offer superior ease of use by integrating with DBT (analyst friendlyness) and simplify the deployment drastically by only being a single binary.
Furthermore, also take note of the new streaming solutions like https://pulsar.apache.org or https://redpanda.com which claim to simplify the streaming story by either allowing unbounded data to be stored in the broker (with tiered storage and both batch and streaming access (which recently partiall was copied by the Confluent Cloud Kafka offering)) or like redpanda offer a drastically simplified deployment using a single binary.
As a further reference see: https://github.com/geoHeil/streaming-reference as a great example how to include NiFi and ELK for Data collection and visualization purposes.
I want to thank https://illlustrations.co/ https://x.com/realvjy for the illustration of the feature image.
