Cost efficient alternative to databricks lock-in

TLDR: Spark-based data PaaS solutions are convenient. But they come with their own set of challenges such as a high vendor lock-in and obscured costs. We show how to use a dedicated orchestrator (dagster-pipes). It can not only make Databricks an implementation detail but also save cost. Also, it improves developer productivity. It allows you to take back control.
Introduction
The big data landscape is changing fast. Spark-based PaaS solutions are part of this. They offer both convenience and power for data processing and analytics. But, this ease has downsides. These include lock-in risks, hidden operating costs, and scope creep. They all reduce developer productivity. This can lead to bad choices. It makes it easy to spend resources without understanding the cost. This often leads to inflated spending. In fact, most commercial platforms try to become all-encompassing. By this they are violating the unix philosophy of doing one thing - but one thing well. This results in further lock-in.
The data we are processing at ASCII is huge. One of the largest datasets we use is Commoncrawl. Every couple of months 400 TiB uncompressed and about 88 TiB of compressed data is added to the dataset. This means optimizing for performance and cost is crucial.
Inspired by the integration of Dagster, dbt and DuckDB for medium-sized datasets. This post shows how scaling this concept to extremely large-scale datasets works, whilst building on the same principles of:
- Containerization & testability & taking back control
- Partitions and powerful orchestration & easy backfills
- Developer productivity
- Cost control
We use Dagster`s remote execution integration (dagster-pipes). It abstracts the specific execution engine. We support the following flavours of Apache Spark:
- Pyspark
- Databricks
- EMR
This lets us make the Spark-based data PaaS platforms an implementation detail. It saves cost and boosts developer productivity. It also reduces lock-in. In particular, it lets us mix in Databricks’ extra capabilities where needed. But, we can run most workloads on EMR for less money. We can do this without changing the business logic. Also, following software engineering best practices for non-notebook development becomes very easy again. This results in a more maintainable codebase. We use ASCII in production. For it, we can observe huge cost savings due to:
- ✅ Flexible environment selection: One job processed commoncrawl data in spark on a single partition. It cost over 700€ on Databricks. There was approximately a 50% Databricks markup for convenience features. Now we only pay less than 400€.
- ✅ Developer productivity & taking back control: Using pyspark locally on small sample data allows rapid prototyping. No need to wait 10 minutes for cloud VMs to spin up. Furthermore, this allows for a fast development cycle & feedback loop.
- ✅ Flexible orchestration: We can easily add partitions and orchestrate steps. We can do this on-premise and in the cloud.
This post is structured as follows:
- Introduction
- Overview of key components
- History overview - the journey to PaaS
- Issues with PaaS
- Vision - combining the best of both worlds
- Implementation showcase
- Dagster pipes introduction
- Application to big data usecase
- Experiences from production
- Conclusion
Overview of key components
Dagster is an open-source data orchestrator. It can run on a single machine and scale to many nodes.
PySpark: is well-known. It is a very scalable data transformation framework. It is famous for making large dataframes accessible to many. It is the backbone of a lot of large-scale data transformations.
PaaS solutions around Spark: We only cover PaaS solutions for Spark. We exclude systems like Snowflake, BigQuery, and Redshift. They are meant for processing tabular data and are optimized for that. Some like BigQuery even allow to process non-tabular data data but are not as flexible as Spark.
Databricks: is rebundling Apache Spark as a managed service. It will have convenience features for Enterprises and Teams. These features include notebook interfaces, a unity catalog, and integrated security. Additionally they improve the performance: Photon. It is a proprietary extension to for faster native data processing. It avoids the JVM overhead.
EMR: Is the AWS flavour of Spark. It has some special optimizations. But, it lacks many of the extras in Databricks’s features. It is quite a lot cheaper though.
The three options offer very different characteristics:
| Feature/Engine | AWS EMR | Databricks | PySpark |
|---|---|---|---|
| Lock-in | low, easyly managed scaling of OSS components 100% OSS API compatible | High, compatible with most clouds, however platform itself has a high lock-in factor | Low, OSS but resource provider is not managed |
| Optimization & scaling | limited, mainly smooth managed scaling | fine-tuned configuration, Photon runtime, latest Delta lake library, managed environment including ML components, enterprise features around access control and data discovery | No - unless custom fine-tuned (i.e. like Facebook does). Scalability depends on the resource provider. In-process local mode is great for testing/CI |
| Cost | Pay-as-you-go, cost-effective for scalable workloads | Pay-as-you-go with approx 50% markup on top of AWS spot instances. Can be expensive if massive compute is needed. Otherwise, offers convenient enterprise features | Free, however resource management for scaling has to be self-handled (requires your time) |
| Ease of Use | Managed scalability, requires high Spark and AWS cloud/EC2 knowledge for fine tunning | Very easy. Pretty much hands-free for most workloads. | Deep understanding of Spark and underlying infrastructure required |
The journey to PaaS
From mainframes to modern cloud solutions
The Beginning: It all started with mainframes. They were the titans of early computing. They paved the way for more specialized data storage.

The web-scale challenge: The challenge was at web scale. As web companies grew, the limits of traditional data warehouses became clear:
- Too pricey for the performance
- Limited IO capacity
- Limited redundancy
They had reached the limit of scaling up and had to figure out how to scale out to multiple cheap machines. The need for scalable, cost-efficient solutions led to the exploration of distributed systems.
The hadoop era: Hadoop was a beacon for those looking to scale out. It let them use many cheap machines without deep dives into distributed systems. Hadoop provided APIs for many programming models. This broadened its appeal beyond its original Java developers. But, map-reduce programming was complex. And the ecosystem initially favored Java. This complexity posed a learning curve for many.
The SQL revolution: The SQL revolution was the introduction of Hive. It added a SQL layer atop map-reduce. This improved accessibility, but was still limited by IO challenges. People wanted faster, easier engines. So, they created Hive-Tez, Hive-LLAP, Spark, Presto, Impala, and Starrocks. These SQL-on-Hadoop engines became key parts of a bigger big data ecosystem. They work with both old data warehouses and new, cloud-native solutions. This reflects the evolution of data technologies. They adapt to meet the ever-growing demands for flexible and scalable data processing.
The shift to PaaS
Despite their advantages, these distributed systems were complex and labor-intensive to maintain. Managed services from PaaS solutions offered an escape. They let you use distributed systems without the work. The industry began to favor PaaS. It is for its scalability, flexibility, and ease of maintenance. This marked a big shift in data processing.
Cloud-based PaaS solutions emerged. Examples include Databricks for Spark and Snowflake for cloud data warehousing. They offer the power of distributed systems without the operational work. These platforms abstracted away the complexities. They provide managed services that are powerful and easy to use.
Issues with PaaS
But, PaaS solutions have had drawbacks. They raise concerns about vendor lock-in and rising costs. Here’s a deeper look into these issues:
Cost concerns: The pricing model of PaaS is tied to usage. This can lead to unexpected and runaway expenses. The platforms have user-friendly interfaces. They lower the technical barriers to entry. This may encourage overuse or misuse, which inflates costs.
Simplicity vs. best practices: PaaS platforms often promote ease of use. They do this through notebook interfaces. But, it comes at the expense of best practices for software engineering. This can lead to oversimplifying complex processes. It results in more lock-in or higher cost. But, it means more revenue for PaaS providers.
Proprietary limitations: Proprietary limitations make it hard to integrate them into independent CI environments. They also complicate self-hosting the solution. The lack of containerization support means you can’t spin up instances. You can’t do this outside the managed system.
Developer productivity: VM based solutions, like EC2, Databricks, and Google Vertex AI notebook, are slow to start. They take 10 minutes to spin up. There is a trend towards serverless SaaS offerings. It reduces the spin-up time, but does not fix the lock-in problem.
Limited customization and control: PaaS platforms provide a high level of abstraction. This makes deployment and management easier. But, it limits how much control and customization developers have. This is important. It is especially true when adding substitutive PaaS can cut costs or at least make them more visible. These limitations are an impediment for productivity.
PaaS at the center of the data engineering strategy
In essence, PaaS solutions offer big benefits. They are better for scalability and ease of use. Often, they become the centerpiece of the data engineering strategy and platform. They are not just an implementation detail in the background. This is leading to potential cost management pitfalls. It’s also causing problems with software engineering principles.
Vision: combining the best of both worlds
- What if we could seamlessly integrate the best features of each PaaS without lock-in?
- How to switch between the providers with zero cost.
From a centralized PaaS to a decentralized ecosystem
Initially, our journey started with a common PaaS solution such as the one depicted below:

It is using a single PaaS. It includes access control. It has a metadata catalog. It has orchestration, notebooks, VCS integration, SQL access, and resource management. We were starting with Databricks (DBR). But, we soon realized that there is an about 50% markup for DBU cost on top of the EC2 spot instance cost. The extra cost of Databricks is usually between 20% and 60% of the total cost. The surcharge for EMR doesn’t usually reach to 30%. This means that in some cases the management surcharge for DBR is higher. It’s higher than the cost for the infrastructure. The cost of the EC2 instances tend to be similar for both platforms (well it is the same AWS base pricing after all). The DBU cost factor we consider above is only for the cheaper job clusters. It is even larger for interactive notebook clusters.
We mainly used Databricks to deploy large Spark jobs. We realized that we might not need all its extra features. Our main goals were to make developers more productive and, to cut the cost of running large jobs. We didn’t need all the services of a single PaaS.
We aim to create a decentralized ecosystem by moving to a PaaS-agnostic approach. This will let us put the PaaS data platform in the background. It is just an implementation detail.
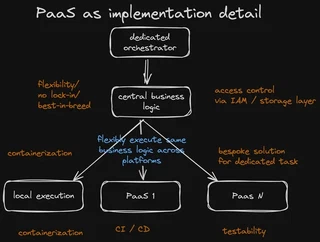
Dedicated orchestrator: A system that separates the orchestration layer from the execution environment. In the case of Dagster, it offers a nice UI. It is for backfills and partitions. Furthermore, it allows us to bridge on-premise and cloud environments. This frees us from the pricingmodel of a single provider.
Central business logic: The central business logic is to increase our choice of tools and services. This will let us tailor our infrastructure to our exact needs.
Improve scalability: Use the best services from multiple providers. This will let us scale our operations up or down based on demand. We won’t be held back by the limits of any one PaaS solution.
The result is a flexible, scalable, and efficient data engineering landscape. In fact, each component is purpose built - i.e. for the data catalog we use Open Metadata. By utilizing these OSS components we achieve the following benefits:
Containerization and local execution: you can run processes locally or in containers. This flexibility ensures robust testing. It boosts developer productivity. It enables fast startups and best practices in software engineering.
Access control via IAM/storage layer: It is centralized and separate from the PaaS platform. It is rooted in the storage layer. This method ensures that access permissions are uniformly managed and enforced. It provides a secure and compliant way to operate.
Bespoke solutions for dedicated tasks: We offer custom solutions for dedicated tasks. You can pick specific PaaS offerings for your needs. This lets you avoid one-size-fits-all constraints.
For us at ASCII it is about all the points - but the major one is cost:
✅ Processing a single month of data (partition) in Databricks cost over 700€. Now, it costs less than 400€.

Implementation showcase
How does it work in practice? Dagster pipes provides a protocol between the orchestration environment (Dagster) and external execution. This includes systems like EMR, Databricks, Ray, Lambda, K8s, and your script. It also provides a toolkit for implementing that protocol.
Exploration of the pipes protocol
The pipes protocol consists of several pieces which need to interplay:
Context injector: The Context Injector is a key part. It configures the environment for a job. It’s responsible for:
- Add important settings. These settings include environment variables. They dictate the job’s runtime behavior.
- It provides job-specific configurations. These include partition information. They are crucial for making data tasks run well.
Message reader, tasked with handling output and communication from the execution environment. Its responsibilities include:
It captures and processes messages from an external process. These include log messages to stdout and stderr. This setup allows for real-time monitoring and debugging.
The logs are designed for monitoring tools like Dagster. They are structured for integration. This enables better observability and insights for operations.
Retrieval of the messages from some persistent globally addressable storage system (S3, DBFs)
Interpreting materialization events and transitioning the neat metadata into dagster
Client, responsible for managing the lifecycle and execution specifics of Spark jobs, including:
You need to configure global Spark settings. They include Delta Lake root configurations. These settings are key for keeping data processing consistent and reliable.
The steps for launching jobs must be defined. This includes picking the right resources, preprocessing, and execution settings.
It handles job termination and retry policies in Dagster. They manage interruptions or errors. It makes sure that resources are cleanly released and that the system stays stable.
Depending on the client, a suitable injector and message reader need to be chosen. For example, the subprocess client has different needs. They are totally different than those of a distributed client, like the one for EMR or Databricks.
External code
The external code is normal python code. It lacks any specific dagster dependencies for the most part. For convenience and better observability, dedicated logging exists. It pushes orchestrator native logs and asset metadata over to Dagster.
def main():
orders_df = pd.DataFrame({"order_id": [1, 2], "item_id": [432, 878]})
total_orders = len(orders_df)
context = PipesContext.get()
print(context.get_extra("foo"))
context.log.info("Here from remote")
context.report_asset_materialization(
metadata={"num_orders": len(orders_df)}
)
if __name__ == "__main__":
with open_dagster_pipes():
main()
Internal Code
The internal code is the code that is running on the dagster instance. Here the metadata about partitions and the environment need to be passed in. Also the file which is to be executed needs to be selected.
@asset
def subprocess_asset(
context: AssetExecutionContext, pipes_subprocess_client: PipesSubprocessClient
) -> MaterializeResult:
cmd = [shutil.which("python"), file_relative_path(__file__, "external_code.py")]
return pipes_subprocess_client.run(
command=cmd,
context=context,
extras={"foo": "bar"},
env={
"MY_ENV_VAR_IN_SUBPROCESS": "my_value",
},
).get_materialize_result()
Application to big data usecase
When applying this in practice for a big data usecase there is a lot more complextity involved. There were two main challenges. No pre-built EMR client for dagster-pipes. Also, the need to inject environment-specific configurations into Spark jobs. Meeting these challenges requires deep understanding of each execution environment. It also needs a strategic approach to implementation. Here’s a structured way to navigate these challenges:
The final result in action
With dagster multiple steps can be chained easily. To showcase the swap of the execution environment: you can see that some assets use Pyspark in local mode. Others use EMR and others use Databricks.

Dagster offers great observability and orchestration capabilities - in particular for multidimensional partitions. We partition the data along two axes: time and domain. Time follows the data’s natural parts. Domain is a custom partitioning. It lets us process different research questions in parallel. For example, we can apply different filters to the graph.
Dagster neatly logs metadata about each asset materialization just like normal native assets.
Architecture deep dive
Factory on dagster side: Develop a dynamic configuration system within the factory. It will automatically detect the target environment and select the right configurations. This involved uploading configuration. It stores environment-specific settings in different cloud PaaS. For example, Spark settings for EMR and Databricks workspace details. The mechanism detects the environment. It uses context, like pipeline parameters and environment variables.
Client: A launcher that can launch the job on the specified execution environment. We made a custom EMR version. It authenticates with AWS using secure credentials. It submits jobs to EMR clusters. It specifies Spark configurations and job dependencies. It gracefully handles job interruptions and errors. This includes cleanup and resource deallocation.
Refinements: We improved the existing Databricks client. This allows for better user experience and fully automatic environment setup. We automated the job definition upload process. We did this by connecting to the Databricks REST API. This streamlined job setup. Implement a bootstrapping mechanism. It automatically sets up the Databricks workspace with needed libraries and packages.
It’s an abstract base class in the remote code. It allows for easy swapping of the execution environment. It also standardizes some common methods and key prefixes. And it unifies IO paths. Lastly, it swaps for the right type of execution engine.
Experiences from production
Challenges of Implementing AWS-EMR
We transitioned to AWS Elastic MapReduce (EMR) to cut costs and gain flexibility. We made the switch from Databricks. However, this transition was far from straightforward. The volume of trial runs required to achieve stability on EMR is high. It shows the complex setup and optimization demands of these platforms. Yet, once set up now, it proves hugely beneficial for us.
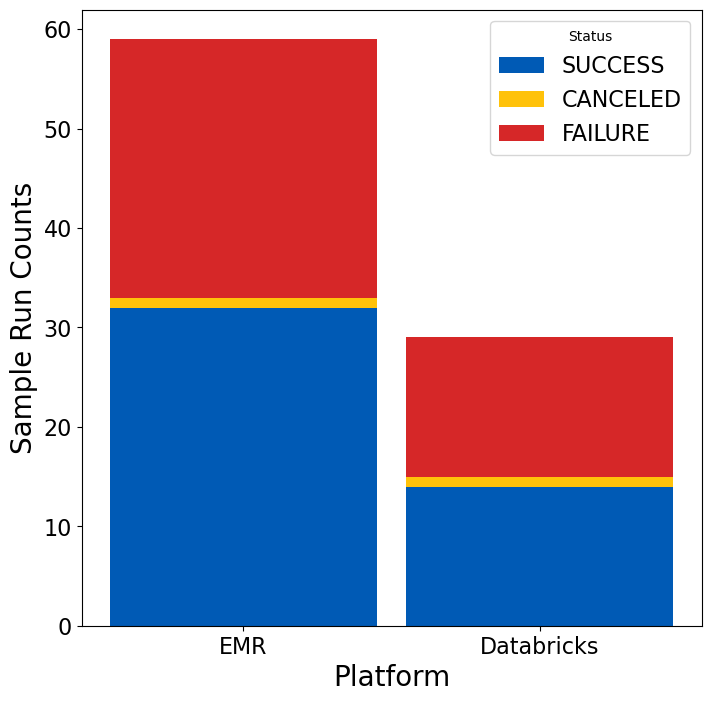
We had used Spark and Databricks before. But, setting up EMR was labor-intensive. This is shown by more failed and successful trials. They happened before the product was ready. In fact we required almost twice as many trial runs for EMR as for Databricks. The increase was mainly due to the complexity of setting up EMR systems. They had to handle large datasets well and safely. This setup needs lots of customization and tuning. Databricks provided these features out of the box.
Knowing the effort to develop and optimize code for AWS Elastic MapReduce (EMR) and Databricks (DBR) can provide more insights. It helps with understanding the operational complexities of these platforms. We made changes to the implementation code for both EMR and DBR. They were made through various pull requests and were systematically different. This is highlighting the additional amount of work involved in setting up EMR.
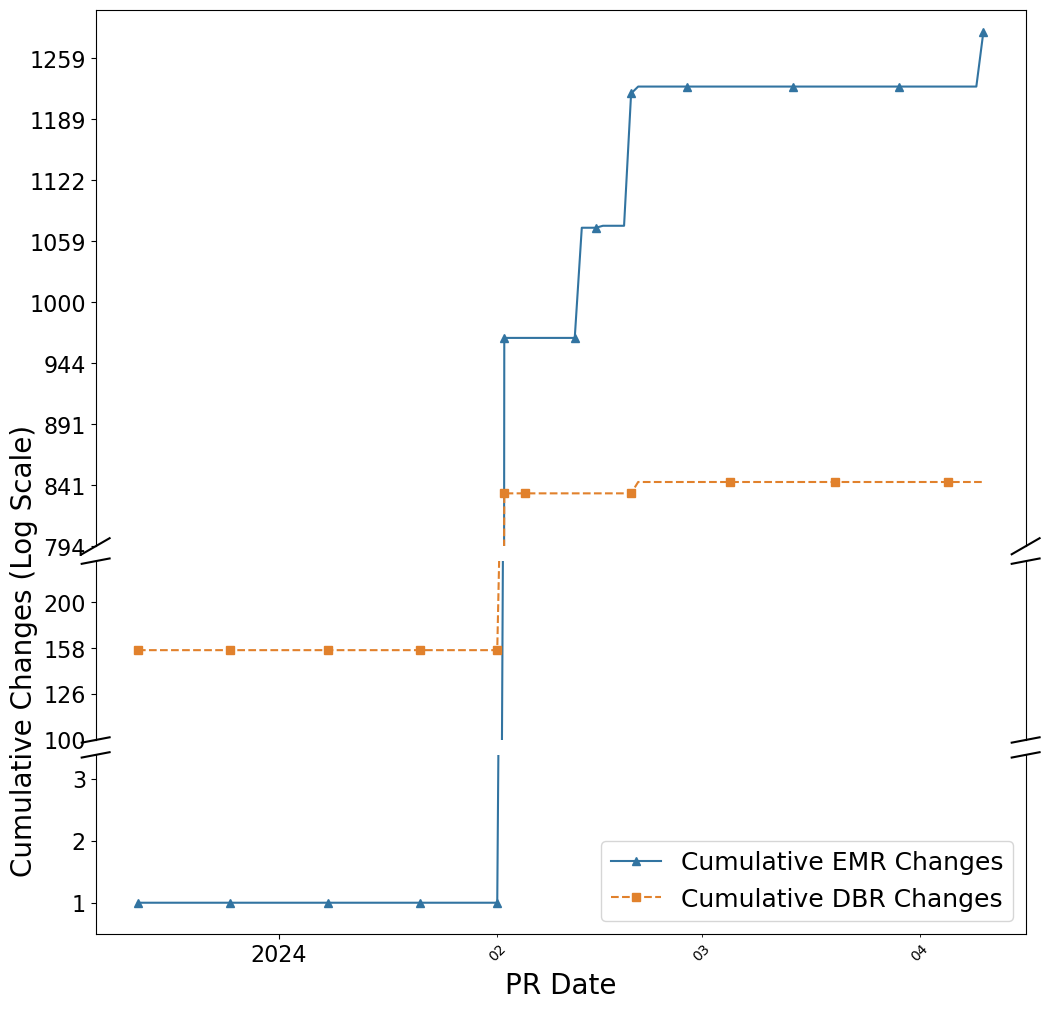
We made big changes to the Python code and configuration files. They were specific to both EMR and Databricks. This differed from what dagster provided out of the box. Once that Databricks was implemented only once lines were added for adjusting performance.
EMR demanded more frequent code changes. They were sometimes extensive. This reflected a steeper learning curve and higher complexity. But, it was in exchange for lower costs.
But, implementing EMR took longer. It also needed many instances of neutral to refine and optimize them. We needed more time and twice the human effort to build a production-grade EMR. This is more than for a production-grade Databricks pipeline.
Our comparison does not count modifications to common files. These files might be for things like visualization or code to be run in the platform.
Cost and performance analysis
When analyzing AWS-EMR versus Databricks, we must consider their cost. This cost includes both the price of computations and the work to set up and maintain them. The following picture provides a clearer picture of the cost metrics:
| Platform | Step | Median | MAD | IQR | N |
|---|---|---|---|---|---|
| AWS-ElasticMapReduce | aws_s3__commoncrawl__edges | 0.36 | 0.11 | 0.21 | 14 |
| aws_s3__commoncrawl__edges | 67.16 | 66.54 | 219.54 | 20 | |
| aws_s3__commoncrawl__graph | 5.53 | 1.17 | 1.88 | 3 | |
| aws_s3__commoncrawl__graph_aggr | 1.42 | 0.98 | 1.49 | 13 | |
| Databricks | aws_s3__commoncrawl__nodes | 0.53 | 0.01 | 0.01 | 2 |
| aws_s3__commoncrawl__edges | 141.10 | 106.60 | 118.97 | 7 | |
| aws_s3__commoncrawl__graph | 11.91 | 4.23 | 10.23 | 22 | |
| aws_s3__commoncrawl__graph_aggr | 0.53 | 0.01 | 0.01 | 2 |
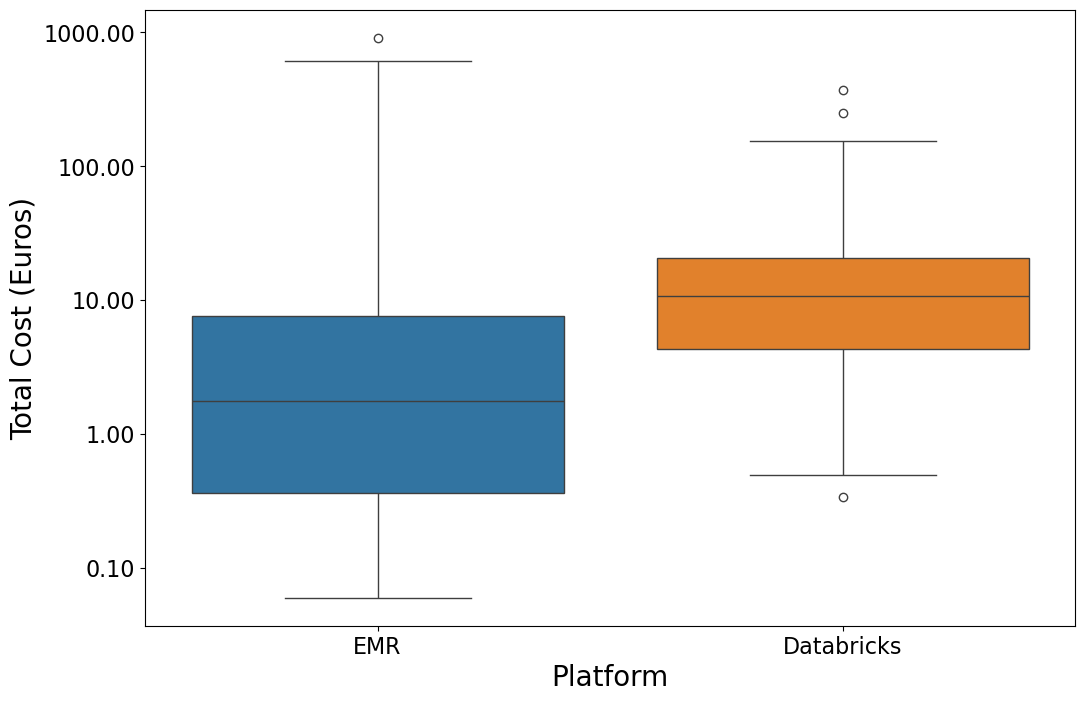
The metrics reveal that DBR often has higher median costs. It also has more variable performance. MAD and IQR show this. But, careful tuning is needed for it to run efficiently. Databricks has less variability and lower costs. This reflects its managed service benefits. They streamline much of the setup and tuning.
An important part of our analysis involved comparing Databricks and EMR. We focused on the time each took to run a step. As expected, Databricks performed better than EMR. It had lower execution times for the same steps. We see this advantage in our metrics. On Databricks, each successful step was shorter than on EMR.
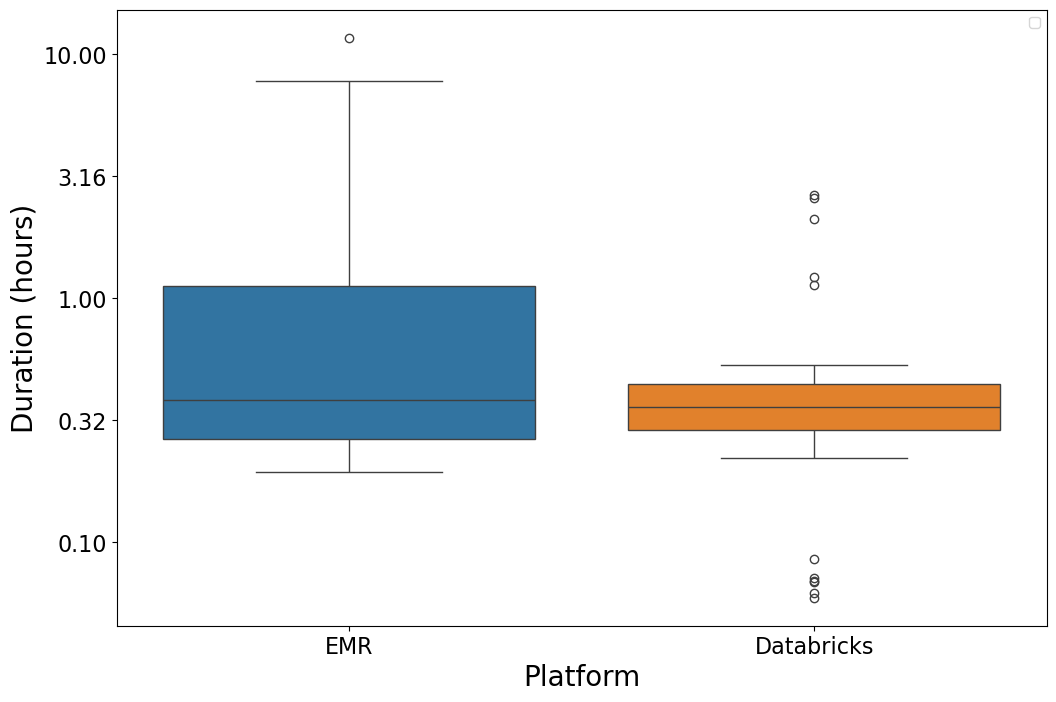
This difference in performance is due to Databricks’ optimized runtime. It has an optimized version of Spark and a c++ re-write (Photon). Photon reduces overhead and execution time significantly. Moreover, Databricks provides fine-tuned configurations out of the box. They allow for faster data processing. You do not need extensive manual tuning, which EMR requires. This shows Databricks is easier to use. It also shows it is cost-effective. It saves resources and time.
For evaluating this pipeline we run it end to end using the same common crawl batch of data:
| PaaS | Total Cost | Platform Surcharge | EC2 Cost | Hours Processing |
|---|---|---|---|---|
| Mix | €393.47 | €213.14 | €173.60 | 11.1 |
| Databricks | €709.62 | €236.09 | €473.53 | 6.4 |
| AWS EMR | €387.87 | €210.52 | €170.47 | 12 |
The table shows that Databricks use greatly increases the total cost of the platform. This is especially true for long, compute-intensive tasks like processing the CC edges. Even for smaller tasks, the Databricks surcharge is a way higher percentage of the total cost. It makes the total cost more expensive. Databricks can speed up data-intensive tasks. This is due to better data processing frameworks. But, they come at a higher cost. The large surcharges observed confirmed this. But, time (operational and human development time) is saved with Databricks.
Lessons learned
Resource configuration is easier with the Databricks JSON format. It is much friendlier than the EMR API. However, with EMR you can and must be more specific. You must say how you will use resources. For example, the support of fleet instance types is fairly involved for EMR. We created a small, somewhat user-friendly compatibility layer. It allows for similar resource configuration for EMR.
Setting up the 0-cost switch between the execution environments was a bit harder than we expected at first. Various small differences need to be taken into account. But now that it is set up it is hugely valuable for us. We had to conquer some complexity. You must carefully consider it if you want to follow along.
Tailoring each to meet needs is time-consuming and complex. Each is for specific operations.
A deep dive into each platform’s default settings is essential. Replicating or improving on these is critical for smooth operation. Databricks is applying some refinements. These need to be replicated on EMR.
Achieving a similar setup on different PaaS platforms is hard. But, it’s essential for valid economic and performance comparisons. This alignment is careful. It ensures accurate data forms the basis of decisions. It can greatly impact the strategy for platform selection and optimization.
Teams need to learn the specifics of each platform. This includes API differences, setup quirks, and best practices. This learning curve can delay initial deployment and require additional training.
Updating the custom compatibility layer is hard. It requires updating any automation scripts to match the latest platform. It takes a lot of resources. You must monitor continuously and update often. This is key to keep efficiency and use new capabilities as they come out.
Switching execution environments without extra costs is great. But, it requires upfront investment in development and testing. This investment is needed to ensure compatibility and performance across platforms.
Understanding each platform’s pricing model is crucial. This includes the cost of compute and storage. It also includes data transfer fees, network usage, and any other hidden costs. These costs could affect the overall price comparison.
It adds a complexity layer. It ensures that all dependencies, libraries, and packages are the same across environments. This prevents discrepancies in runtime behavior.
Configuration tips
Use this property when launching an EMR cluster group. It doesn’t work for fleets. See https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark-configure.html#emr-spark-maximizeresourceallocation:
"Properties": {"maximizeResourceAllocation": "true"},Interestingly, fixing some of the EMR’s fine-tuning issues requires doubling the memory. It is still cheaper than Databricks. But, it might run a bit longer.
Delta lake tables can run ZORDER optimizations not only on the full table. You can optimize arbitrary partitions or subsets:
df = DeltaTable.forPath(spark, io_edges) df.optimize().where(f"seed_nodes='{part_seed}' AND crawl_id='{part_cc}'").executeZOrderBy(["src_url_surt_host", "src_url_surt"])Use LZO compression has a good tradeoff between compression ratio and cpu-time. Interstingly, https://docs.databricks.com/en/query/formats/lzo.html is not required anymore for DBR-14.3 as the libraries seem to be already present.
To fix slow
vacuumoperations such as (https://stackoverflow.com/questions/62822265/delta-lake-oss-table-on-emr-and-s3-vacuum-takes-a-long-time-with-no-jobs, https://github.com/delta-io/delta/issues/395) set:spark.databricks.delta.vacuum.parallelDelete.enabled=truehttps://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hadoop-task-config.html for understanding memory availability for EMR in fleet mode
cloudwatch logs for EMR https://aws.amazon.com/de/blogs/big-data/monitor-apache-spark-applications-on-amazon-emr-with-amazon-cloudwatch/
ensure the application master is not running on spot instances https://repost.aws/knowledge-center/emr-configure-node-labeling-yarn
yarn.node-labels.enabled": "true", "yarn.node-labels.am.default-node-label-expression": "CORE"
Conclusion
We have shown that putting Spark-based PaaS data solutions in the background saves a lot of money. It also boosts developer productivity. The authors encourage others to follow this path to indepdence and cost savings.
For us at ASCII having the flexibility to mix the workloads of both providers has been a game changer. For massively scalable map transformations we can use EMR for cheap processing. Workloads benefit from Photon. They would otherwise get stuck in JVM garbage collection. We can use Databricks. By merging the best of both worlds, we save a lot of money. We can also offer a much better developer experience. Indeed, Databricks is great and a offers a convenient experience - fairly hands-off. Most things magically simply just work. This is different for EMR, more fine-tuning is required.
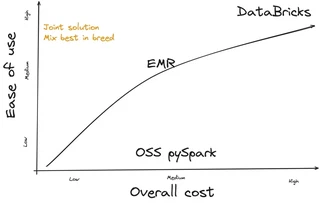
For small-ish to medium workloads EMR works fine out of the box => we can save money (cheaper compute)
For very large workloads, we use EMR with fine-tuning. It lets us save money with cheaper compute.
For special workloads, Photon is very profitable. We use Databricks to save money and time again.
Call to action
We look beyond traditional data engineering. We see the thrilling potential of Spark-based architectures. They are free from proprietary lock-ins. Become a part of the unfolding story by engaging with our community on GitHub.com/l-mds.
Future outlook
The future is bright. It promises fast tech for the masses. It’s like the JVM but not. It’s Velox and Arrow Datafusion Comet. They light paths never traveled before. Databrick’s photon engine used to be proprietary. Now, it’s coming to the community through these OSS alternatives.
https://arrow.apache.org/blog/2024/03/06/comet-donationTIL about Apache DafaFusion Comet. @apple has replaced @ApacheSpark's guts with @ApacheArrow DataFusion. And they're donating it. 🤯https://t.co/yIyrFpuYmc
— Chris (@criccomini) February 6, 2024
This is an alternative to @MetaOpenSource's Velox Spark implementation.https://t.co/VIGpFYDnyt
/ht @philippemnoel pic.twitter.com/leAVBE2g5b
Furthermore, these principles of independence also apply to other domains such as LLMs: https://www.neutrinoapp.com is delivering massive cost reductions there with similar principles about putting established PaaS solutions into the background.
Further reading:
- Importance of composable data management systems
- Dagster-pipes documentation. The code example from above is taken from there.
Some of the images were created using AI - Firefly by Adobe and dallE. Parts of this text were created in a refinement loop with AI: human input - AI (GPT-4) and human refinement.


Researcher at the Supply Chain Intelligence Institute Austria (ASCII).
My research interest lies at the intersection of forecasting extreme events and causal analysis in high-frequency time series.