Rediscovering the SUPER in Supercomputing

Hydrating supercomputers with Dagster and Slurm to enhance developer experience.
Quick overview
High-performance computing (HPC) powers many of humanity’s most ambitious challenges—from climate modeling and materials research to large-scale AI and simulations. Yet while hardware performance has advanced, developer experience on supercomputers often feels behind.
HPC users still rely mainly on handwritten Slurm scripts, ad-hoc environment management, and limited observability. Meanwhile, modern data teams orchestrate complex, multi-language workflows using tools like Dagster, Airflow, Prefect, enjoying dependency graphs, retries, lineage tracking, and cloud-native visibility.
dagster-slurm bridges that gap.
It lets the same Dagster assets run seamlessly across laptops, CI pipelines, containerized Slurm clusters, and Tier-0 supercomputers — no code changes required.
👉 Repo: ascii-supply-networks/dagster-slurm 👉 Docs: ascii-supply-networks.github.io/dagster-slurm
HPC systems and their challenges
Supercomputers deliver massive compute power, but their interfaces haven’t kept up. Typical workflows look like this:
- Writing and debugging long
sbatchscripts. - Waiting in queues with little visibility.
- Managing dependencies via modules or environment files; often using plain Conda environments
- Rewriting code to move from local prototypes to production clusters.
- Accessing and maintaining logs is tedious.
The result is slow iteration, brittle reproducibility, and limited observability — all the things data orchestration tools were built to solve.
A European GPU cloud will not come out of nowhere. We have to make the existing GPU capacity usable for a larger audience and ensure better utilization.
This project may pave the path for more streamlined usage of HPC GPU compute in Europe and was supported by the EUROCC AI Hackathon
Dagster and Dagster Pipes
Dagster is a modern data orchestrator designed around assets — the data products your code produces. It brings dependency tracking, retries, rich metadata, and strong observability to data and ML pipelines. It is commonly used in non-HPC environments. For example also in the enterprise. Further, this technology may be well suited for sovereign data and AI platforms as presented recently at a TDWI roundtable.
Dagster Pipes extends that power beyond Dagster’s own process. It provides a simple protocol for running and observing remote workloads, regardless of environment — from Docker containers to HPC clusters. One example is to save 50% off of spark/databricks cost by following the approach outlined in this blog post.
With Pipes, Dagster can:
- Launch and monitor jobs running anywhere (including over SSH or Slurm).
- Stream logs and metrics back in real time, and push configuration to the remote environment
- Stay scheduler-agnostic while preserving lineage and observability.
This foundation makes Pipes a perfect match for the HPC world — where isolation, reproducibility, and visibility are non-negotiable.
Dagster-Slurm
dagster-slurm builds on Dagster Pipes to connect Dagster’s orchestration model with Slurm’s powerful scheduler.
It delivers the developer experience of modern data platforms on top of the reliability of HPC systems.
🚀 Key features
- Seamless portability — Run the same asset locally or on a supercomputer by toggling an
ExecutionMode. - Automatic packaging — Uses Pixi and
pixi-packfor reproducible, portable environments. - Flexible launchers — Choose between Bash, Ray, or custom runtimes.
- Deep observability — Slurm job metrics and logs stream directly into the Dagster UI.
🧩 Example
import dagster as dg
from dagster_slurm import ComputeResource, RayLauncher
@dg.asset
def training_job(context: dg.AssetExecutionContext, compute: ComputeResource):
completed = compute.run(
context=context,
payload_path="workloads/train.py",
launcher=RayLauncher(num_gpus_per_node=2),
resource_requirements={
"framework": "ray",
"cpus": 32,
"gpus": 2,
"memory_gb": 120,
},
extra_env={"EXP_NAME": context.run.run_id},
)
yield from completed.get_results()
Switch from ExecutionMode.LOCAL to ExecutionMode.SLURM — and the same asset now submits via sbatch, runs on the cluster, and streams logs back to your Dagster UI.
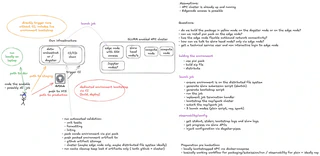
🧠 Architecture highlights
dagster-slurm consists of three main layers:
- Resources — encapsulate SSH access, Slurm queues, and execution modes (
ComputeResource,SlurmResource, etc.). - Launchers and Pipes clients — handle environment packaging, job submission, and log/metric transport.
- Operational helpers — utilities for SSH pooling, heterogeneous jobs, and queue observability.
This layered design keeps user code agnostic to the underlying transport while retaining full visibility through Dagster’s orchestration plane.
See below an in-depth description of the various components and their interactions.
Summary
dagster-slurm combines the best of both worlds:
- The observability, lineage, and ergonomics of Dagster.
- The scheduling power and scale of Slurm.
No more rewriting scripts, no more opaque queues — just reproducible, testable, observable workflows that scale from your laptop to Tier-0 supercomputers.
Rediscovering the “SUPER” in supercomputing isn’t about faster hardware. It’s about empowering researchers, engineers, and data scientists with modern tools that make that hardware accessible, productive, and even enjoyable to use.
This work was kindly supported by:
- ASCII
- CSH
- EUROCC AI Hackathon: This work was completed in part at the EUROCC AI Hackathon, part of the Open Hackathons program. The authors would like to acknowledge OpenACC-Standard.org for their support.
- Austrian Scientific Computing (ASC)
🧩 Learn more

Researcher at the Supply Chain Intelligence Institute Austria (ASCII).
My research interest lies at the intersection of forecasting extreme events and causal analysis in high-frequency time series.
