Simple Sovereign Scalable Data Stack

Cloudflight Office Walcherstraße 1A, Stiege 3, 3. Stock 1020 Wien Austria
Tired of cloud lock-in and surprise bills?
Join us for a practical talk on building a fast, portable, and sovereign data & AI stack with:
- DuckDB
- Dagster
- Ray
- Small Language Models
We’ll cover:
- A short history of SQL-based data processing and where DuckDB fits in
- How pg_duckdb extends DuckDB with Postgres strengths
- What “Ducklake” means for simpler data lake/lakehouse collaboration
- Running and scaling Small Language Models for audio & document tasks with Ray & Docling
- use case 1: audio transcription
- use case 2: document preprocessing for RAG
- Tying it all together into one orchestrated, sovereign stack
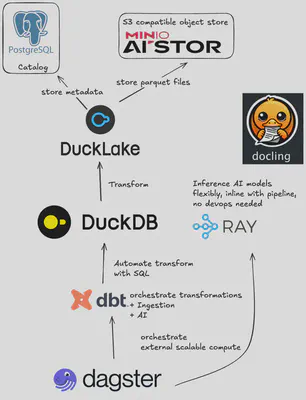
Takeaways:
- How to build a souvereign yet powerful BI/data stack under your control
- How to orchestrate beyond just tables into documents and AI workloads
- A practical sense of Small Language Models and how to scale them sovereignly with Ray
Recording
official event description
👋 Hi hi,
Our 21st event is coming up on Wednesday, October 22nd and we will be hosted and sponsored (snacks & drinks at the event) by Cloudflight! 💜
As usual, first we will have food and drinks and then, as of 6:30PM, we will start with our evening program.
Looking forward to seeing many of you there! Rigerta
Agenda:
18:00 - Doors open; food & drinks 🍔
18:30 - Welcome talk by Cloudflight
18:40 - Georg Heiler - Simple souvereign scalable data stack (+Q/A) Tired of cloud lock-in and surprise bills? Join us for a practical talk on building a fast, portable, and sovereign data & AI stack with: DuckDB Dagster Ray Small Language Models We’ll cover: A short history of SQL-based data processing and where DuckDB fits in How pg_duckdb extends DuckDB with Postgres strengths What “Ducklake” means for simpler data lake/lakehouse collaboration Running and scaling Small Language Models for audio & document tasks with Ray Tying it all together into one orchestrated, sovereign stack
19:30 - Break 🥤
19:45 - Markus Thaler - Apache 3.0: the OG data orchestrator re-thought (+Q/A) Earlier this year, Apache released Airflow version 3.0, posing a big update to one of the most popular open-source workflow orchestration tools in the data engineering landscape. This presentation will look at the newly introduced features, which are intended to bridge gaps to more modern data orchestrators. In a short demo, we will explore how the new features work in action. Further, we will also examine whether they solve Airflow’s common pain points and how the new version compares to other tools like Dagster and Prefect. By the end, you’ll have a clear idea of what is new, how the features work and if Airflow 3.0 is the right choice for your workflows.
21:00 - End
Speakers:
Georg Heiler is a researcher at TU Wien & Complexity Science Hub Vienna and a Senior Data Scientist at Magenta Austria. Georg’s interests are in working with large-scale spatio-temporal graph data. He considers an end-to-end view of the data pipelines and holistic data architecture. As an experienced data scientist in the industry, he has delivered use cases concerning fraud detection, mobility analytics and predictive maintenance in cable networks.
Markus Thaler is a Data Engineer at Cloudflight with a background in data science and text mining. Fighting unreliable data earlier in his career got him into building data pipelines. Now he made it to his passion to make sure that what comes out on the other end is fresh and clean.
Location:
Cloudflight Office Walcherstraße 1A, Stiege 3, 3. Stock 1020 Wien Austria
👋 Don’t forget to RSVP!