Lean and efficient MDS experience: Delivers better software engineering practices to the data ecosystem with the new local MDS stack comprised of Dagster, dbt and DuckDB which offers better developer productivity by enhancing testability of the E2E pipeline.
🔐 Exploring the power duo of Mozilla's sops & AGE for secret management! Dive deep into their benefits: simplicity, version control compatibility & robust encryption. Secure your data the modern way! 💻🛡️ #ITSecurity #Encryption #DataProtection
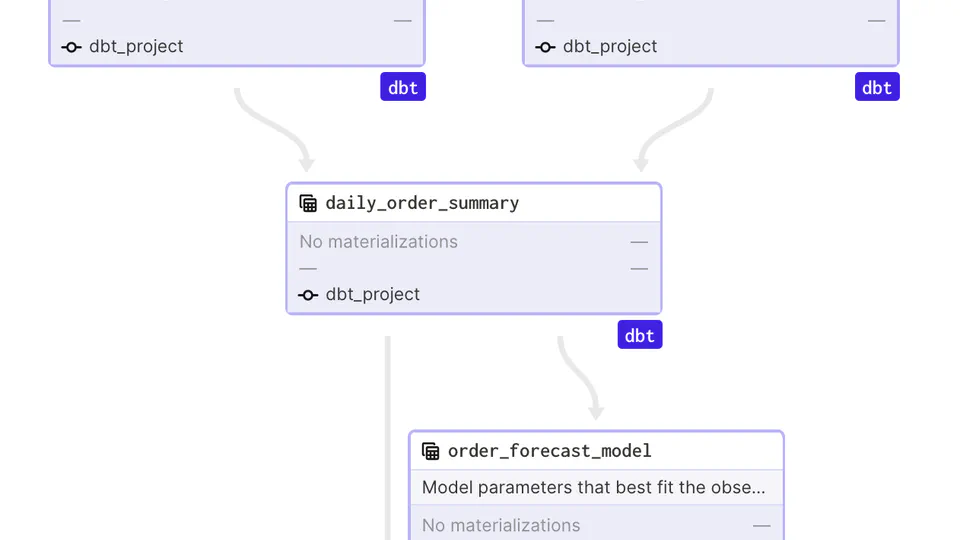
📊 Unleash the power of metadata extraction in your data engineering pipelines with the new DBT API in Dagster! 🚀 Learn how to seamlessly integrate and leverage DBT transformations, while enriching your data catalog with advanced metadata. Elevate your data governance and collaboration to new heights!
Towards simpler and perhaps more energy efficient data platforms with increased developer productivity.
Comparing established and up-and-coming streaming approaches for an integrated real-time data model
Way too many data pipelines still work with SFTP file transfer. Even a modern data orchestrator needs to interface here well.
Simplify data ingestion with the plentiful connectors of Airbyte without compromising on data lineage
Getting started with simple dagster pipelines.
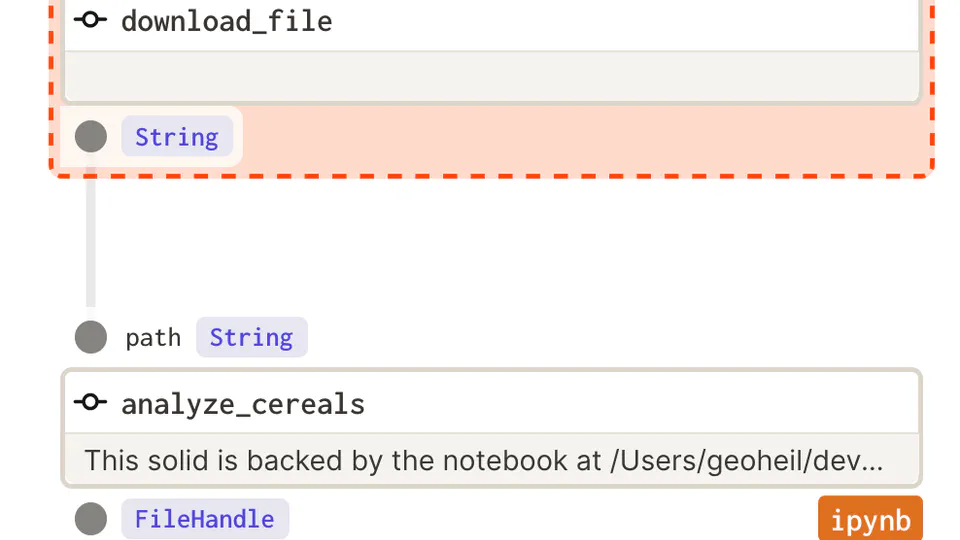
Include jupyter notebooks into reliable data pipelines.
A full example E2E