Flip the data pipeline to get a better notion about the things we actually care about: data assets not transformations.
Getting started with simple dagster pipelines.
Overview over the modern data stack ecosystem. Introduction to this blog series
Interacting with a running dagster instance interactively
Using Apache Spark for **sparse** matrix multiplication
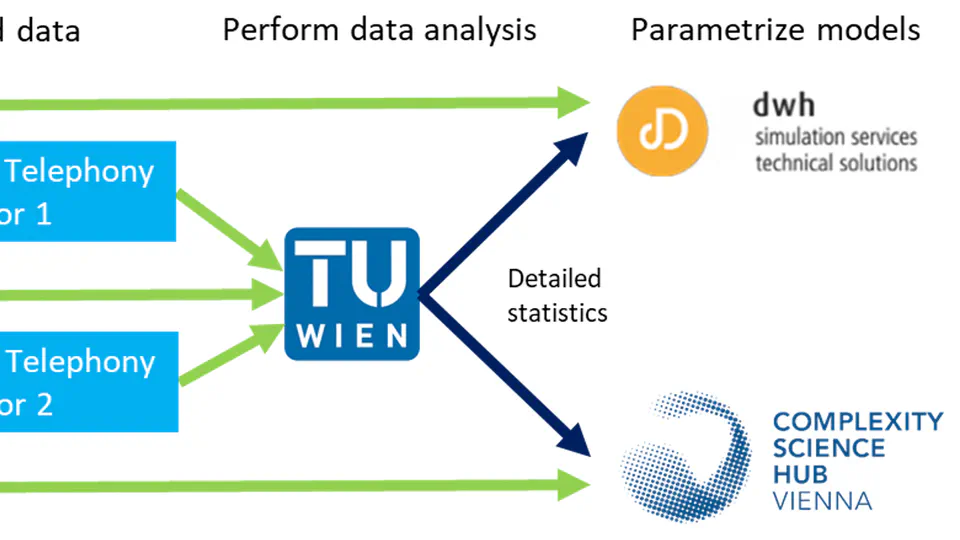
WWTF COVID project summary
Easy configuration handling for complex machine learning pipelines
Guaranteed anonymity in high-dimensional data using differential privacy
Useful links
Combining the power of Scala and Python to make the calculation of percentiles in Spark easy and fast