Upskilling data engineers

I frequently receive mentoring requests both online as a moderator on the data engineering subreddit and in person. This comprehensive guide compiles essential resources and principles for data engineering, enabling focused discussions on more advanced topics. Feel free to reach out after reviewing these fundamentals.
Certain topics are just briefly touched on and may warrant further explanation in a separate post.
The request for mentoring
Most mentoring inquiries share common themes, revealing core principles that aspiring data engineers should master.
Common mentee profiles include:
- Complete newcomers to the field
- Professionals transitioning from related disciplines
- Career changers seeking new opportunities
In a couple of rare and select cases the situation is a bit different: It is not just online but real. Personal. When mentoring my bachelor’s, master’s and PhD students. Interestingly, for these rare cases, I ended up with fairly close collaboration on some projects I care about - and sometimes even hired the people.
Reality check
Online mentoring challenges
Many potential mentees fail to address fundamental questions:
- What does ideal mentoring look like for you?
- Are you seeking specific answers or guidance on forming better questions?
- What are your concrete goals and timeline?
When these questions are answered, I typically explore their context and objectives while sharing my background and resources like this blog. Interestingly, even initially enthusiastic candidates often drop off. This is not necessarily bad for me - as it would be rather tricky to justify the time spent on mentoring without commitment. But I have to say, I still do enjoy sharing knowledge and encouraging people to build towards a brighter data future. In fact, decodinglove.tv, so far a stealth project of mine, is all about that.
In-person mentoring
Face-to-face mentoring typically yields better results. These interactions tend to:
- Show higher commitment levels
- Present more complex, interesting challenges
The challenges these people face are often more complex and interesting - and as a result often also their questions less repetitive.
Key principles
Data engineering can be challenging.
3 key challenges in informatics are: state management, off-by-one errors and use-after-free errors (nullability).
If you want to learn about data engineering you have to master at least one of these challenges.
- State management means dealing with state over time, storing it, and handling the intricacies of evolving schema
- Off-by-one errors refer to different means of indexing data structures. Some data is indexed from 0, some from 1.
- Use-after-free errors (basically accessing data which is not there anymore) is a common issue in particular for low level languages like C and a major security issue
Master the real-world data challenges
Is big data dead?
You have to decide for yourself.
What is for sure is: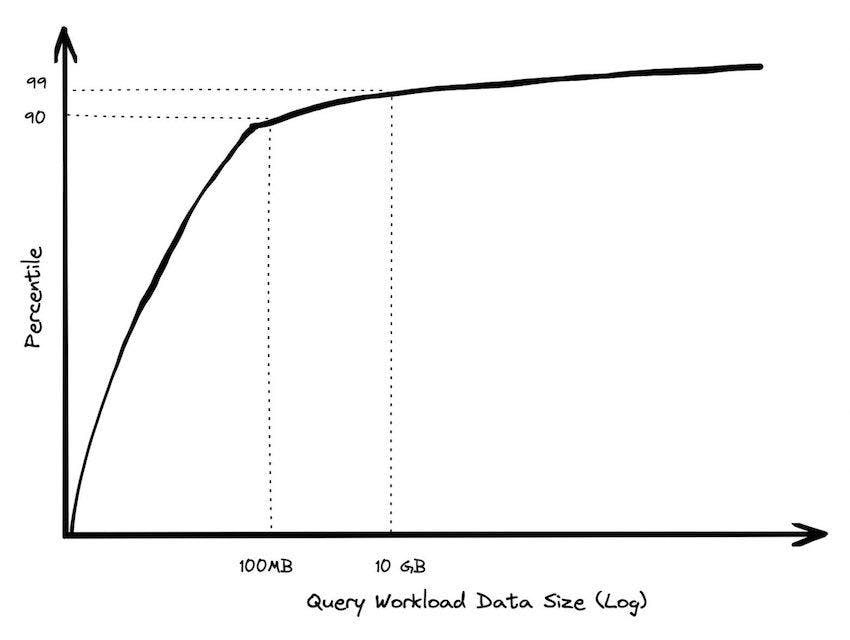
- The dataset size workload in most cloud data warehouses( snowflake, bigquery, redshift) is not big (data). At least not for the largest part of their tables.
- Finding hardware and software which handles the data challenges of most (non-big-tech) companies is not hard or expensive.
Some voices clearly mention, that the world is more complex. While this is true, the principles I share below, are even applicable for these larger workloads as well.
Local first
Back in the old days, Oracle offered a one-stop-shop solution for the data needs of most organizations. It even offered data virtualization, a capability which is nowadays often sought after by dedicated vendors - due to highly complex stacks. The data needs were simpler, but the technical capability was also limited.
Do not get stuck in a single database –> orchestrate
With the rising importance of data, managers wanted to learn more about the “now”, not the “what happened last month”. Some even wanted to learn more about the future.
Oracle had one big issue with AI - there was no AI inside Oracle - or the SQL standard. So a lot of people resorted to using something else - often a rather poor or not efficient solution. One of the main challenges was getting data out of Oracle and pipe it through some AI process - whilst still keeping the state in sync overall. Eventually, most data teams ended up with sending their data to a cloud-based data warehouse as these are self-optimizing and make complex challenges seem (deceptively) easy. However, it turns out most datasets and query patterns are rather small.
Most data fits into RAM.
You can cheaply rent servers with up to roughly 32TB RAM in AWS as of 2025. This is a lot of data - with no complexity of a distributed system. And if you need more compute: NVIDIA’s H200 has 141 GB of fast HBM RAM and can massively improve the performance via RAPIDS (if needed):
- For data-frames https://github.com/rapidsai/cudf
- For computations https://github.com/cupy/cupy
- For graphs https://github.com/rapidsai/cugraph
You can even pair up a larger number of accelerator cards in a single server (usually up to 8) and combine the memory of all the accelerator cards.
Data has gravity and locality. Data applications should work - even when offline. Learn more about localfirstweb.dev. Understand the advantage of being able to scale down a complex data pipeline to a single developer’s laptop. This allows smooth onboarding of new people - and also simpler debugging of the pipeline in case something goes wrong.
Local does not mean single-node or limited!
Local does not mean single-node or limited! Given a suitable resource provider (kubernetes, lambda functions, a supercomputer, …) you can scale the pipeline as much as you need. But not as a distributed system - you can operate per partition which each behaves like a simple but performant single-node system.
If your data-needs ever outgrow what your local laptop or server can provide - there are a lot of options. You do not need to move straight into the territory of complex distributed systems:
- Firstly, use an orchestrator like dagster or prefect and ensure your data assets are partitioned
- Make sure to trigger your pipeline incrementally and only for the partitions that have changed
- If a lot of partitions need to be processed, use kubernetes or lambda functions as the resource provider for execution to scale the execution your pipeline easily
- You may find value in incremental computation to further reduce resource consumption https://github.com/feldera/feldera
- Look at https://github.com/deepseek-ai/smallpond for scaling duckdb
- https://www.getdaft.io/ for scaling in a data-frame -based approach even to multiple nodes
- Last but not least learn about Ibis. This is a data-frame library with pretty much arbitrary backends - from duckdb to bigquery to Thesus on a supercomputer.
- And understand what idempotency is and why it matters.
- Distributed systems can be an option
- Like https://spark.apache.org or the cloud data warehouses like snowflake, redshift, bigquery.
- For extreme data-needs a supercomputer like Theseus may be needed
- A system like Doris or Starrocks may allow you to scale the workload if you reach the limit of per-partition operations given IO, memory or compute constraints. The interesting thing is that Starrocks pretty much behaves like a standard RDBMS to the outside. But beware of the performance and fine-tuning details which such a system may require.
- If you follow the principles above you can:
- Choose any resource provider flexibly even a SaaS one
- You are not tied to any specific transformation or storage engine
- You can easily combine multiple engines to achieve the best of both worlds and save money
The power of the asset graph
Make sure all the steps in your data pipeline are part of a graph. With this you do not need to fight the computer or the data(dependencies). Instead, by choosing the right - graph-based data structure of explicit data dependencies they can become your friend. Now, the computer can reason about the data and help.
Ensure that:
- Ingestion
- Transformation
- Validation/testing
- AI workloads (even LLMs and agents)
- BI visualization https://github.com/dagster-io/dagster/pull/27218 are part of the graph
When you accomplish this you gain:
- Operational lineage: The connections of the dataflow are a given, correct and do not need to be re-engineered -Event-based connections and communication between the data assets and tools
- This can even allow for neat data virtualization capability
- This allows for a more scaled approach to handling data in a large organization whilst keeping everyone (remember the state management challenges) in sync.
- You can reduce tool silos
- This leads to better and more direct communication of the many data handling departments in a larger company.
- This even allows for simplified onboarding of end-user (citizen data scientists) code by embracing the work of these people in the graph and thus allows you to further scale data handling capabilities to a wider variety of people.
Metadata
Ensure you collect suitable data about your data (metadata). It should not only be prose text but a machine-readable specification.
If you at a later point in time ever want to expose this data - perhaps to business departments via a semantic layer so that they can chat with their data you will thank yourself for ensuring high quality machine-readable metadata is available.
Communication
For many companies data is a supporting function. It is crucial to effectively communicate with the stakeholders to understand their needs - but also to explain in laymen terms what you have to offer. It is not about the data and the tools - rather about selling. What may help:
- Practice on the job 😄
- Write a personal blog to practice your writing skills
- Speak at conferences or meetups
Data projects often do not fail due to technology:
Some first steps
Read
Understand the tools which allow you to be efficient (and learn how they work)
Explore: the local data stack template which bundles a lot of these best practices and tools into a single easy-to-use package. And see also: https://georgheiler.com/post/lmds-template/
Other neat resources:
- https://dataengineering.wiki/Guides/Getting+Started+With+Data+Engineering
- https://www.ssp.sh/book/
- https://github.com/gunnarmorling/awesome-opensource-data-engineering
- https://awesomedataengineering.com/
- https://github.com/igorbarinov/awesome-data-engineering
- https://dagster.io/blog/partitioned-data-pipelines
- Understand the differences between SQL traditional RDBMS, NoSQL, MPP (massively parallel processing) database systems
Interesting thoughts for further exploration:
- Saving serious money with a good orchestrator - reducing PaaS lock-in
- Learn more about devops and SRE practices
Frequent misconceptions
- My data size is so big I need to use spark on 10GBs of uncompressed CSV files.
- No seriously do not do this.
- Any distributed system will be slower than an optimized single-node engine like duckdb.
- Data is not about coding - it is SQL only
- To architect the system you must understand how to code
- To build sensible abstractions you have to understand how to code
- In any case you have to understand how to empower other people to do more with data and coding background will be useful for that.
- I need a costly and complex data copy solution
- Maybe duckdb can do it: They have a phenomenal CSV reader but also support for reading Excel files no seriously their geospatial extension is not only fast but packaged with the simple deployment of a single binary but conveniently allows to access many specialized file types in the GIS ecosystem
- Last but not least dagster’s embedded elt which can use Sling or dlt probably has you covered very well.
- It will not cost a large amount of money if a SaaS vendor of choice changes their event/volume-based pricing model to be more expensive
- the ingestion but also other steps of the graph are linked natively
- I need all the latest and greatest shiny AI tools
- No, you do not. At least not at the start.
- Get your basic data needs in order and deliver value to the business:
- Handle the past: Standard reporting
- Cleaning data
- Tackling metadata and semantics
- Machine-readable definition of KPI in semantic layer
- Handle the now: operational data needs (speed, anomaly detection)
- Explore the future (predictions)
- Understand how evolving data needs such as LLMs and agents map to what you already have:
- Semantic layer (if you are lucky) and have curated the executable specification of your metadata
- Orchestration: The graph is key. Understand the additional value of dedicated LLM agentic orchestrators and balance the tradeoff with the existing one that you (hopefully) have. The value of a single shared graph for a large amount of data needs is highly beneficial
- Handle the past: Standard reporting
Some questions I have encountered recently
- Internally, I have developed a library for ETLs with streamlined solutions for common problems. However, on Youtube and other places I always see people building from the ground up and coding a lot of stuff?
- A lot of Youtube content is geared either towards beginners or as marketing material of a specific vendor meant to be very easily consumable. This means glossing over certain details and complexities of real-world usage. Real world usage most likely will be more complex. Often data teams internally will create certain tools/scripts/libraries to make their life easier
- This idea of medium code: https://dagster.io/blog/the-rise-of-medium-code is a quite interesting one
- How to handle data testing (coming from a traditional ETL background) how is this handled for large data (how do you guys unit test 1tb data…; I see logging used mostly… but it is not possible to do if data is huge…)?
- You can define data tests in SQL or high code and execute these tests alongside the main transformation step
- There are some vendors which try to sell you on running tests outside of the pipeline like https://www.montecarlodata.com/blog-data-observability-vs-data-testing-everything-you-need-to-know/
- I would recommend though to make testing part of your pipelines and not one more external siloed tool
- You need to differentiate multiple types of testing (unit, integration, snapshot testing, load testing, input fuzzing and also data testing, user acceptance testing, UI testing, stress testing). traditional means of testing usually test the stateless code. As you have realized this can be problematic with data
- Logging is a possibility: There is always the option to implement a dead letter queue if you want to do this or rather halt the downstream processing or like Netflix only publish after vetting (WAP https://blog.det.life/how-does-netflix-ensure-the-data-quality-for-thousands-of-apache-iceberg-tables-76d3ef545085) in case of failing data quality tests - up to you/your use case. Netflix is following https://lakefs.io/blog/data-engineering-patterns-write-audit-publish/ the WAP strategy - i.e. staging the data, testing it and then only after successful tests making it available to consumers. This is done with some new possibilities offered by the open table formats
- We have been working in MPP architecture - so I was quick to relate spark as similar.
- How can I very fast copy files between databases?
- Ideally you do not need to copy at all
- Understand the bulk mode
- Instead of JDBC/ODBC Arrow ADBC is structured in a columnar layout for even better performance
- https://github.com/sfu-db/connector-x may be worth a look
- often for more reproducible results and less raw speed https://slingdata.io/ or https://dlthub.com/ wrapped in https://docs.dagster.io/integrations/libraries/embedded-elt can be really interesting
I will add more Q/A pairs here over time which may be of value to more people.
Amendments from commenters
keeping up-to-date
finding a job
- stand out as an analyst https://plotsalot.slashml.com/blogs/stand-out-as-a-data-analyst?utm_source=lo#lets-build-our-story
Organization
- Find a good engineering team to join as a junior. A team where seniors are willing to mentor and that has the required level of safety so team members can learn from both each others and their own mistakes and successes. But learning from failure is more important as it takes more guts to even admit such and tells factually positive things about the teams psychological safety, which is as far as I know, the most important factor for learning in a team environment. https://www.linkedin.com/in/juuso-montonen-7127ab20 https://rework.withgoogle.com/en/guides/understanding-team-effectiveness#introduction https://www.youtube.com/watch?v=BsYIvi3Sae8
Summary
Mentoring can be useful but it is hard to scale efficiently. Personal connections tend to be more effective than online ones. Especially for the online mentees, the questions are often shallower and repetitive - I hope this list of resources is useful for you and can get you started to ask more interesting questions.
Many thanks to the reviewers for their valuable feedback: